一段C级别的源码,编译在不同指令集上,最终功能一致,这固然理所应当。但它却能做到在汇编层面,以黑客ROP视角的高度统一,使自己能够跨越不同指令集成为真正的通用gadget,仔细想想会觉得很神奇,再多想一点可能会感到暗藏杀机。
历史考古
第一次听到通用gadget还是原老师当助教时说的,那是2019年9月,我研一,当时对通用二字倍感惊奇。最近有缘要好好看看这个gadget,回顾历史发现,这东西的正式提出基本认为是18年的blackhat:
但此论文居然将这个并不复杂的技术写了20多页,并且没有说明白这段gadget产生的本质:
为什么会有这段gadget?glibc太复杂,他们也不知道…
6.1 Why is this gadget here?
First of all, the complexity of the glibc is so high that it is very hard to find the ultimate
reason for some design decisions. Some design choices were motivated by other architecture
restrictions which are not applicable to ours. In other cases, the fear to break others
code or to cause baroque backward compatibility issues makes the developers to follow
the solid premise that "if it ain’t broke, don’t fix it".
另外其实2016年,蒸米的系列文章:一步一步学ROP之linux_x64篇 中,就有所提及通用gadget。在twitter上搜 universal ROP 还能搜到14年,11年老外发的相关推文:
- https://twitter.com/ockeghem/status/495531933791567872
- https://twitter.com/agixid/status/106829539128246273
所以最早是谁提出的,不太容易考察,也没有太大的必要,但是大部分对此gadget的提及都是关于x64,包括blackhat的论文和蒸米的博文,当然x86这种以栈传参的指令集不需要研究怎么控制参数寄存器。但除了我们熟悉的x64:
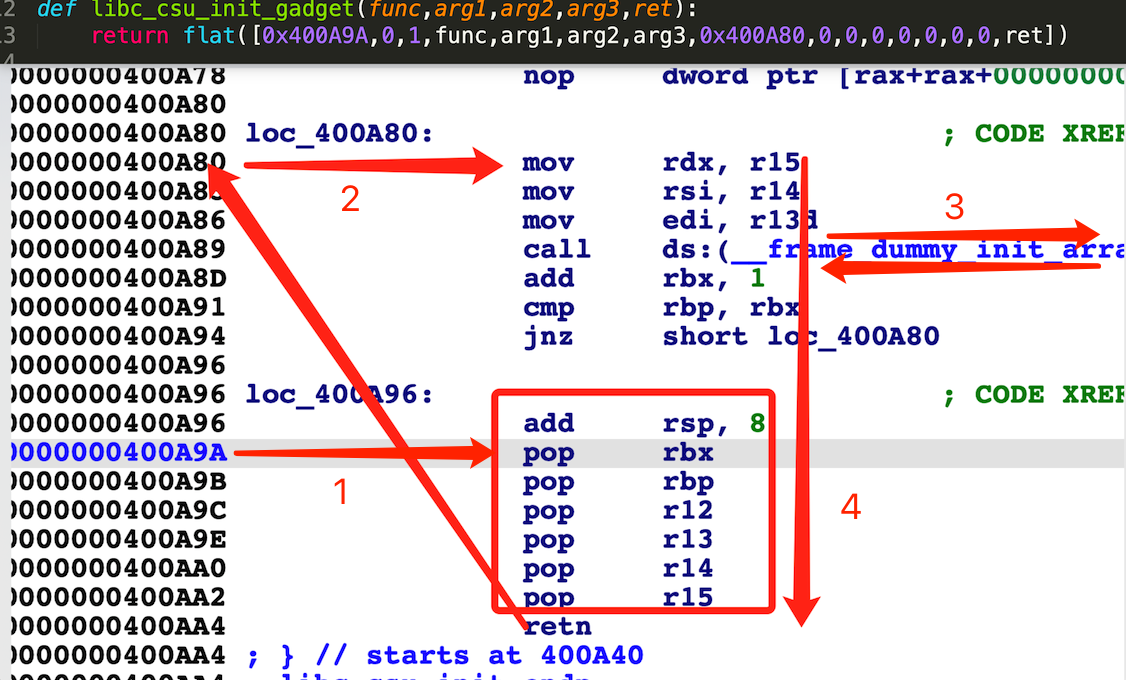
其他指令集也能使用此gadget,如ARM/ARM64:
也如MIPS,虽然由于s系列寄存器的缘故,ROP本就很好找,但此gadget仍然有效:
这就很有意思了,就历史资料来看,通用gadget中通用的本意是x64下对于大部分应用程序来说的通用,因为只要是编译工具链是glibc的套件,就应该会带 __libc_csu_init 函数。但现在看起来,这个通用直接跨越了各种指令集,使其成为各种指令集下,各种应用程序中都包含的一段可从栈上控函数参数并调用的真·通用gadget。这神奇的一段gadget背后的本质道理到底是个啥呢?
我的理解
所以必然要回到 __libc_csu_init 这个函数的实现,虽然这个函数在ELF中,但其源码依然实现在glibc中,以2.27为例,其位于:csu/elf-init.c,glibc 2.34后有所改动。
CSU 的含义是 “C Start Up” : What does CSU in glibc stand for?
void __libc_csu_init (int argc, char **argv, char **envp)
{
_init ();
const size_t size = __init_array_end - __init_array_start;
for (size_t i = 0; i < size; i++)
(*__init_array_start [i]) (argc, argv, envp);
}
我认为,这段代码能够跨越不同架构成为通用gadget的道理就是这个代码模式:
- 函数的三个参数参数会原封不动的透传到下一个通过函数指针调用的函数中
- 并且在透传之前还有其他的函数调用
这就导致了:
- 存在可以直接控制流劫持的寄存器
- 参数寄存器由于其他函数调用不得不备份到其他寄存器
- 当透传函数被调用时又必然要从其他寄存器中恢复参数
- 若其他寄存器是函数调用上下文不易失的,则被调用函数需完成寄存器的备份与恢复(如同mips的s系列寄存器)
- 大量寄存器的备份与恢复就是靠栈,这与指令集无关,或者说大家都是这么干的
所以构造如下控制流:
- 先从栈中恢复其他寄存器
- 然后从其他寄存器恢复参数与控制流寄存器
这即是通用gadget,总结下来就是代码特性加上指令集共性导致的神奇结果。所以如果使用上下文不需要恢复的寄存器系列,如mips的t系列寄存器,这段就废废了。但由于函数指针是循环调用,所以即使是mips,也必然不会用t系列寄存器。
编码测试
以上都是我自己的分析,那是不是这么回事呢?自己动手写一下就知道了!环境如下:
➜ uname -a
Linux ubuntu 4.15.0-162-generic #170-Ubuntu
➜ gcc -v
7.5.0-3ubuntu1~18.04
按照刚才说的模式写一段:
int(*p[100])(int,int,int);
int c(int x,int y,int z){
return x+y+z;
}
int b(){
return 0;
}
int a(int x,int y,int z){
b();
p[0](x,y,z);
return 0;
}
int main(){
p[0] = c;
a(1,2,3);
}
直接编译:
➜ gcc test.c -o test
IDA观察,结果是不用费力倒腾寄存器了,直接从栈上出来了,但栈是由rbp寻址的,不能直接利用:
; Attributes: bp-based frame
public a
a proc near
var_C= dword ptr -0Ch
var_8= dword ptr -8
var_4= dword ptr -4
; __unwind {
push rbp
mov rbp, rsp
sub rsp, 10h
mov [rbp+var_4], edi
mov [rbp+var_8], esi
mov [rbp+var_C], edx
mov eax, 0
call b
mov rax, cs:p
mov edx, [rbp+var_C]
mov esi, [rbp+var_8]
mov ecx, [rbp+var_4]
mov edi, ecx
call rax ; p
mov eax, 0
leave
retn
; } // starts at 621
a endp
模拟的更像一点,加上一个循环:
int(*p[100])(int,int,int);
int c(int x,int y,int z){
return x+y+z;
}
int b(){
return 0;
}
int a(int x,int y,int z){
b();
for(int i=0;i<10;i++){
p[0](x,y,z);
}
return 0;
}
int main(){
p[0] = c;
int x,y,z = 1;
a(x,y,z);
}
结果和之前一样,想了好久为啥不对,突然想到了优化,加了O2:
➜ gcc test.c -O2 -o test
就和目标差不多了:
.text:0000000000000660 loc_660: ; CODE XREF: a+2F↓j
.text:0000000000000660 mov edx, r12d
.text:0000000000000663 mov esi, r13d
.text:0000000000000666 mov edi, r14d
.text:0000000000000669 call qword ptr [rbp+0]
.text:000000000000066C sub ebx, 1
.text:000000000000066F jnz short loc_660
.text:0000000000000671 pop rbx
.text:0000000000000672 xor eax, eax
.text:0000000000000674 pop rbp
.text:0000000000000675 pop r12
.text:0000000000000677 pop r13
.text:0000000000000679 pop r14
.text:000000000000067B retn
想想也对,循环里肯定还是寄存器快,每次都从栈上来是慢。所以综上,大概原理分析的是对的,不过真要达成和目标汇编完全一致的代码细节方面更需要一丝不苟。
修复方案
既然知道这种gadget的代码模式:
- 函数的三个参数参数会原封不动的透传到下一个通过函数指针调用的函数中
- 并且在透传之前还有其他的函数调用
一般来说破坏即可,但启动过程牵一发动全身,blackhat的论文中的修复方案看起来都动作挺大的,分析这里约束:
- __init函数必须在
- 调__libc_csu_init时参数必须传好
- 未来调函数指针时也必须要用这些参数
这导致调__init函数时必将保存参数寄存器到其他地方,由于__init为外部函数,编译器不知道其行为,所以如果无人工干预,最终参数无论倒(二声)了几层寄存器,必然要存到栈上,导致此gadget的存在似乎是一种必然。但其实ROP最重要的是栈,故只要打破参数是从栈上来的即可破坏此gadget,所以,直接把三个参数拷贝成全局变量,调用时从全局变量中取出即可:
int(*p[100])(int,int,int);
int c(int x,int y,int z){
return x+y+z;
}
int b(){
return 0;
}
int xx,yy,zz;
int a(int x,int y,int z){
xx = x;
yy = y;
zz = z;
b();
for(int i=0;i<10;i++){
p[0](xx,yy,zz);
}
return 0;
}
int main(){
p[0] = c;
int x,y,z = 1;
a(x,y,z);
}
gadget成功消失:
.text:0000000000000650 push rbp
.text:0000000000000651 push rbx
.text:0000000000000652 lea rbp, p
.text:0000000000000659 mov ebx, 0Ah
.text:000000000000065E sub rsp, 8
.text:0000000000000662 mov cs:xx, edi
.text:0000000000000668 mov cs:yy, esi
.text:000000000000066E mov cs:zz, edx
.text:0000000000000674 jmp short loc_692
.text:0000000000000674 ; ----------------------------------------------------------
.text:0000000000000676 align 20h
.text:0000000000000680
.text:0000000000000680 loc_680: ; CODE XREF: a+48↓j
.text:0000000000000680 mov edx, cs:zz
.text:0000000000000686 mov esi, cs:yy
.text:000000000000068C mov edi, cs:xx
.text:0000000000000692
.text:0000000000000692 loc_692: ; CODE XREF: a+24↑j
.text:0000000000000692 call qword ptr [rbp+0]
.text:0000000000000695 sub ebx, 1
.text:0000000000000698 jnz short loc_680
.text:000000000000069A add rsp, 8
.text:000000000000069E xor eax, eax
.text:00000000000006A0 pop rbx
.text:00000000000006A1 pop rbp
.text:00000000000006A2 retn
版本演变
发现glibc2.34版本中把初始化这段放到了 csu/libc-start.c 中:
static void
call_init (int argc, char **argv, char **envp)
{
/* For static executables, preinit happens right before init. */
{
const size_t size = __preinit_array_end - __preinit_array_start;
size_t i;
for (i = 0; i < size; i++)
(*__preinit_array_start [i]) (argc, argv, envp);
}
# if ELF_INITFINI
_init ();
# endif
const size_t size = __init_array_end - __init_array_start;
for (size_t i = 0; i < size; i++)
(*__init_array_start [i]) (argc, argv, envp);
}
看起来gadget的特征还存在,不知道会不会有其他的变化…