正向开发是理解一个复杂系统的必要过程,我们熟悉linux用户态的Pwn,是因为随手就能写出一个helloworld,然后编译、运行、逆向、调试一条龙,进而理解它完整的生命周期。linux内核Pwn的文章有很多,不过大都是以完成一道题目的视角行文的。而本文希望,我们能熟悉内核态的代码的运行状态,具体来说就是:在 ubuntu20.04 (linux 5.11.0-25) 的本机环境下完成 ① 正向开发:将我们的代码送进内核态运行,了解有哪些可以使用的内核函数,基于这些函数实现一些功能。② 内存调试:使用log大法看到内核的内存。③ 内核本体:不同于源码视角,我们要找到内核二进制代码本体,认识一下。
攻击概述
这并不是我第一次接触内核态代码的运行:
基础的内核Pwn题多是出在外挂的内核模块上,而不是内核本体,对于内核本体的漏洞只接触过一次,且没有调试过:
不过由于内核模块和内核本体处于同一种运行状态,即内核态(x86的ring0,ARM的EL1),所以对二者的攻击效果是一致的,这个层次的最高目标就是拿到内核态的代码执行权限。按照攻击者位置划分,一般有三种攻击入口:
- 用户态打内核态:接口是所有中断,即引发用户态陷入内核的所有入口,最常见的就是系统调用,系统调用里最常见的就是ioctl,如:许多CTF题目 Linux Kernel Pwn 初探
- 从外设打内核态:接口是各种外设的输入,比如空口(wifi、蓝牙等)、线缆(USB、TCP/IP等)、平行系统间(TEE与REE)的通信报文,如:Bleeding Tooth:Linux蓝牙驱动远程代码执行分析与利用、在Tesla Model S上实现Wi-Fi协议栈漏洞的利用、探索澎湃S1的安全视界
- 更底层控内核态:已经能控了内核态的更底层(x86的ring-1/2/3,ARM的EL2/3),则可直接控制内核态的代码执行,如:checkra1n、checkm30,注:负的CPU保护环
打下内核的代码执行权限后的目标一般有两种:
- 控用户态:对用户态(x86的ring3,ARM的EL0)进行彻底的控制,突破其安全措施(自主访问控制,SELinux等),进而获得用户态的最高权限,这也是最常见的目标。
- 往底层、其他系统打:拿到了通往底层、其他系统的更广阔的接口,如:利用 ARM 核间调试漏洞获得 SoC 硬件最高权限(上)、利用 ARM 核间调试漏洞获得 SoC 硬件最高权限(下)
最常见的组合就是:从用户态打内核态,目标是打回到用户态的最高权限,即本地提权:Local Privilege Escalation (LPE),更多内容也可以参考ctf-wiki:https://ctf-wiki.org/pwn/linux/kernel-mode/basic-knowledge/
正向开发
以下示例代码力求最简,目的是让读者看的清楚,所以什么编码规范,线程安全,都不予考虑,我也不会。
基础知识
首先发现了写的挺好的一个系列:
- linux模块编程(一)—— 加载你的模块
- linux模块编程(二)—— 运行不息的内核线程kthread
- linux模块编程(三)—— 线程的约会completion
- linux模块编程(四)—— 消息的使者list
- linux内核的学习方法
正向开发必然要回答一个问题:我可以使用哪些函数?这其实就是内核API,首先想到的就是printk,那么除了printk还可以使用哪些函数呢?可以在内核的官方文档里搜索:
另外也有基于linux 3.19.3版本的书:
但在接下来的实践里我们会发现一些人困惑的现象:
- 用户态API可以查询man手册,但内核API没有找到相应的手册
- 一些API官方文档无法查到,但是可用,比如
kernel_read - 一些API在不断的变化,并且没找到一个详细的版本说明
后来看到了:The Linux Kernel Driver Interface以及Linux kernel interfaces也就明白了,主要是责任和限制:
- 内核开发者的数量要远小于应用开发者,所以linux内核并不需要像一门编程语言,对API的稳定所负责
- linux内核希望他们的开发是个轻骑兵,灵活且自由,技术在变革,接口也应该不断优化,不应该被稳定所限制
所以linux内核并不对提供稳定的API而负责,故在我们开发内核态代码时,很多API需要自己去找,去搜,去看源码才能明白原理以及用法,另外其实只要是使用了EXPORT_SYMBOL导出的函数,都可以成功使用。不过这并不意味着我们不需要知道一个API过去的故事,因为从学习与反思的角度来看,向后看就是向前进。另外,不稳定的API除了给我们学习带来一些困惑,还会不会带来其他问题呢?
- Linux 是否被过誉了?
- 为什么 Linux 在桌面会失败?
- “Unstable kernel APIs” vs. the embedded reality :-(
- 再谈Linux内核模块注入(没有kernel header也能hack kernel)
想了解更多linux内核可以常逛 Linux Weekly News:https://lwn.net/
helloworld
自然免不了俗,首先是最简单的,随处可见的helloworld:
https://github.com/xuanxuanblingbling/linux_kernel_module_exercise/blob/master/01.hello/hello.c
#include <linux/init.h>
#include <linux/module.h>
MODULE_LICENSE("GPL");
static int hello_init(void)
{
printk(KERN_INFO "Hello, world!\n");
return 0;
}
static void hello_exit(void)
{
printk(KERN_INFO "Hello, exit!\n");
}
module_init(hello_init);
module_exit(hello_exit);
编译,安装模块,查看dmesg,成功打印helloworld:
$ ls
hello.c Makefile
$ make
make[1]: Entering directory '/usr/src/linux-headers-5.8.0-63-generic'
CC [M] /mnt/hgfs/桌面/kernel/hello/hello.o
MODPOST /mnt/hgfs/桌面/kernel/hello/Module.symvers
CC [M] /mnt/hgfs/桌面/kernel/hello/hello.mod.o
LD [M] /mnt/hgfs/桌面/kernel/hello/hello.ko
make[1]: Leaving directory '/usr/src/linux-headers-5.8.0-63-generic'
$ sudo insmod hello.ko
$ dmesg | tail -n 1
[ 2009.281102] Hello, world!
$ sudo rmmod hello
$ dmesg | tail -n 2
[ 2009.281102] Hello, world!
[ 2021.107657] Hello, exit!
以上我们的printk打印代码,成功的运行在了内核态,不过这个代码只在模块安装时触发运行。
watchdog
之前在调试一个基于海思hi3518解决方案的摄像头时,只要gdb把目标进程挂上,系统不一会就重启了,开始以为是有其他进程检测反调试,不过我把其他看起来有关的进程全部干掉后,仍然没用。后来发现了一个[hidog]内核线程,看起来就是看门狗功能,经过对目标程序的逆向,发现的确有个线程在不断的ioctl一个dev目录下的watchdog设备文件。最开始想的验证以上推测正确与否的思路是字节写一个不断ioctl的代码交叉编译上去,不过因为内核版本和交叉编译工具不太合适,一度陷入放弃。但最后猛然找到了对应的内核模块文件wdt.ko,由于此系统的文件系统可以修改,并且发现此模块是开机后才安装的,所以直接把wdk.ko删掉了,重启后挂gdb则不会重启,可以正常调试了。
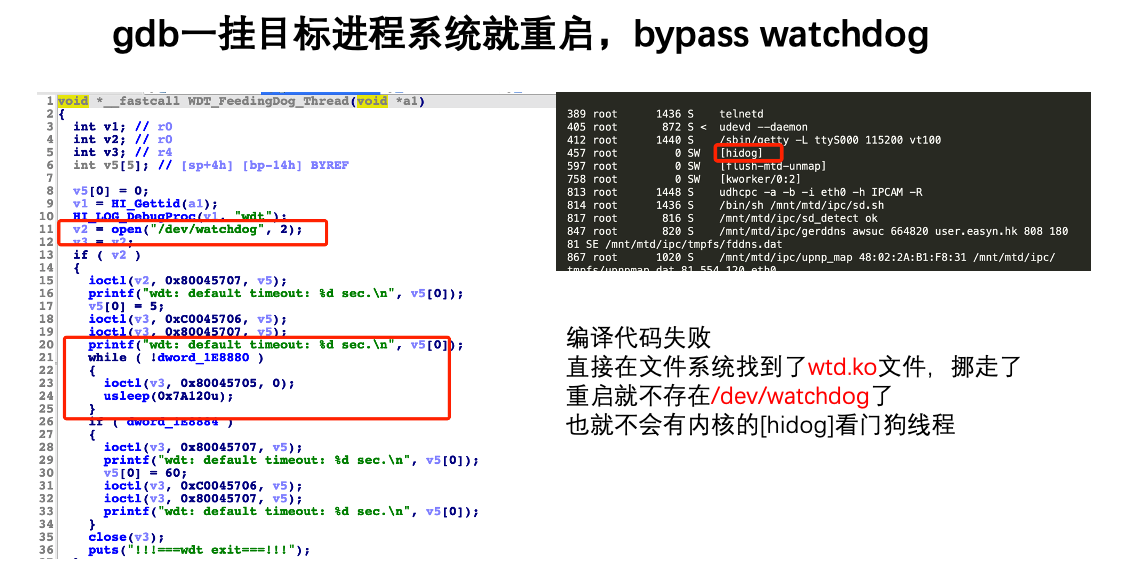
所以wdt.ko运行起来的内核线程[hidog]就是看门狗本狗,目标进程的不断ioctl的线程就是喂狗。这里的内核代码与刚才只运行一次的helloworld不同,[hidog]一直在运行,那么内核模块里如何启动一个内核线程呢?这里我自己复刻了一个:
https://github.com/xuanxuanblingbling/linux_kernel_module_exercise/blob/master/02.hidog/hidog.c
主要是有一个全局变量clock,在一个一直循环的线程里自增,当其大于30时,系统重启。主要是使用了内核线程这一套api:kthread_create_on_node, wake_up_process, kthread_should_stop, kthread_stop,看门狗线程由init模块初始化时拉起,模块卸载时终止。另外使用了proc_create, remove_proc_entryproc文件系统的api生成了一个接口文件,当open这个文件时,clock清空。重启的API为emergency_restart。
#include <linux/init.h>
#include <linux/module.h>
#include <linux/reboot.h>
#include <linux/kthread.h>
#include <linux/delay.h>
#include <linux/proc_fs.h>
MODULE_LICENSE("GPL");
struct task_struct * result;
int clock;
int dog(void * argc)
{
while(!kthread_should_stop()){
ssleep(1);
printk(KERN_INFO "hidog clock: %d\n",++clock);
if(clock>30) emergency_restart();
}
return 0;
}
int hidog_open(struct inode *inode, struct file *file){
clock = 0;
return 0;
}
const struct proc_ops myops = {
.proc_open = hidog_open
};
static int hidog_init(void)
{
printk(KERN_INFO "hidog, init!\n");
result = kthread_create_on_node(dog, NULL, -1, "hidog");
wake_up_process(result);
proc_create("hidog",0666,NULL,&myops);
return 0;
}
static void hidog_exit(void)
{
kthread_stop(result);
remove_proc_entry("hidog", NULL);
printk(KERN_INFO "hidog, exit!\n");
}
module_init(hidog_init);
module_exit(hidog_exit);
相关API的学习文章:
- Linux内核的延时函数
- Linux内核API kthread_create_on_node
- kthread_create_on_node和kthread_stop
- linux模块编程(二)——运行不息的内核线程kthread
- kthread_should_stop()这个函数干了什么?
- How to fix error: passing argument 4 of ‘proc_create’ from incompatible pointer type
- https://lynxbee.com/linux-kernel-module-to-reboot-the-system-using-emergency_restart-api/
编译,安装,即可看到有了[hidog]内核线程:
$ make
make[1]: Entering directory '/usr/src/linux-headers-5.11.0-25-generic'
CC [M] /home/xuanxuan/linux_kernel_module_exercise/02.hidog/hidog.o
MODPOST /home/xuanxuan/linux_kernel_module_exercise/02.hidog/Module.symvers
CC [M] /home/xuanxuan/linux_kernel_module_exercise/02.hidog/hidog.mod.o
LD [M] /home/xuanxuan/linux_kernel_module_exercise/02.hidog/hidog.ko
make[1]: Leaving directory '/usr/src/linux-headers-5.11.0-25-generic'
$ sudo insmod ./hidog.ko
[sudo] password for xuanxuan:
$ ps -ef | grep hidog
root 24750 2 0 15:21 ? 00:00:00 [hidog]
xuanxuan 24866 2337 0 15:22 pts/0 00:00:00 grep --color=auto hidog
然后使用dmesg即可看到令人紧张的计时,如果不做任何操作,你的电脑将在30s后重启:
$ watch -n 1 "dmesg | tail -n 5"
Every 1.0s: dmesg | tail -n 5 ubuntu: Thu Aug 5 15:31:42 2021
[ 419.164103] hidog clock: 1
[ 420.188266] hidog clock: 2
[ 421.212630] hidog clock: 3
[ 422.235847] hidog clock: 4
[ 423.260249] hidog clock: 5
此时如果cat一下/proc/hidog文件,计时则会退回到0,并重新开始自增,可以循环cat,即喂狗:
$ while true; do cat /proc/hidog || sleep 1; done
所以我们的watch窗口也可以观察到clock变量,令人放心的1,电脑不会重启:
Every 1.0s: dmesg | tail -n 5 ubuntu: Thu Aug 5 15:34:48 2021
[ 605.861439] hidog clock: 1
[ 606.885639] hidog clock: 1
[ 607.908981] hidog clock: 1
[ 608.933025] hidog clock: 1
[ 609.957441] hidog clock: 1
所以当喂狗的进程或者线程失效后,clock继续自增,系统重启。
文件读写
网上能找到许多例子:
- 内核态文件操作
- 在linux内核中 读写上层文件
- Linux内核下读写文件
- linux内核编程-内核态文件操作
- Read/write files within a Linux kernel module
但按照如上方法在本机上(linux 5.11.0-25)编译会有如下报错:
error: implicit declaration of function 'get_fs'; did you mean 'get_sa'?
error: implicit declaration of function 'set_fs'; did you mean 'sget_fc'?
error: 'KERNEL_DS' undeclared (first use in this function); did you mean 'KERNFS_NS'?
发现是新版本把set_fs()废弃了,但怎么解决读文件的问题却没找到,看起来set_fs()和读文件也没什么强相关:
- Doesn’t build with linux kernel 5.10+
- Saying goodbye to set_fs()
- How to replace set_fs(KERNEL_DS) for a kernel 5.10.x module driver version
- Linux Kernel 5.10-RC1发布:弃用可追溯到初版的set_fs ()功能
- Linux 5.10 finally ditches decades-old tool that caused security bugs
那到底怎么读文件呢?当搜索这个问题时,很多答案会反问你,你为什么要在内核态读文件呢?原来在内核开发者眼里,由于性能以及安全风险,读文件这种功能应该交给用户态程序,而不应该在内核中完成:
- Driving Me Nuts - Things You Never Should Do in the Kernel
- File I/O in a Linux kernel module
- An in-kernel file loading interface
这也是内核开发和应用开发的区别,目标不同,思路也就不同。读文件,这个在用户态的应用程序看起来再正常不过的操作,在内核态居然是万人嫌。不过话说回来,内核态程序和用户态程序虽然目标不同,但其本质的最大差别就是运行时CPU特权级不同,而且本身读写文件系统这个功能就是内核完成的,按道理内核一定可以直接读写文件,不信你看:
他们都提到了kernel_read这个函数,用处是在加载ELF和底层固件时读文件,而且第一篇文章也很困惑为什么找不到这个函数的资料。那我们可以通过搜索头文件和看函数符号的方法来看看这函数到底能不能用:
$ sudo cat /proc/kallsyms | grep " kernel_read"
ffffffff93111860 T kernel_read
$ grep -Rn " kernel_read(" /lib/modules/5.11.0-25-generic/build
./include/linux/fs.h:2860:extern ssize_t kernel_read(struct file *, void *, size_t, loff_t *);
还真能用,我们可以进一步找一下这个函数的实现,果然被导出:
https://github.com/torvalds/linux/blob/master/fs/read_write.c
ssize_t kernel_read(struct file *file, void *buf, size_t count, loff_t *pos)
{
ssize_t ret;
ret = rw_verify_area(READ, file, pos, count);
if (ret)
return ret;
return __kernel_read(file, buf, count, pos);
}
EXPORT_SYMBOL(kernel_read);
那就使用kernel_read来读取一个只有root用户可以读取的flag文件吧:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/fs.h>
MODULE_LICENSE("GPL");
static char buf[100];
mm_segment_t old_fs;
static int readfile_init(void)
{
struct file *fp;
loff_t pos = 0;
printk("readfile enter\n");
fp = filp_open("/flag", O_RDWR ,0);
kernel_read(fp, buf, sizeof(buf), &pos);
printk("read: %s\n", buf);
filp_close(fp, NULL);
return 0;
}
static void readfile_exit(void)
{
printk(KERN_INFO "readfile, exit!\n");
}
module_init(readfile_init);
module_exit(readfile_exit);
编译,安装,成功读取到flag:
$ ls -al /flag
---------- 1 root root 23 Aug 5 09:20 /flag
$ cat /flag
cat: /flag: Permission denied
$ sudo cat /flag
flag{this_is_the_flag}
$ make
make[1]: Entering directory '/usr/src/linux-headers-5.11.0-25-generic'
CC [M] /home/xuanxuan/linux_kernel_module_exercise/03.readfile/readfile.o
MODPOST /home/xuanxuan/linux_kernel_module_exercise/03.readfile/Module.symvers
CC [M] /home/xuanxuan/linux_kernel_module_exercise/03.readfile/readfile.mod.o
LD [M] /home/xuanxuan/linux_kernel_module_exercise/03.readfile/readfile.ko
make[1]: Leaving directory '/usr/src/linux-headers-5.11.0-25-generic'
$ sudo insmod ./readfile.ko
$ dmesg | tail -n 1
[ 408.529461] read: flag{this_is_the_flag}
但在insmod处执行一定是root权限,所以使用了一个proc文件系统的接口来让普通用户触发内核读取文件:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/proc_fs.h>
MODULE_LICENSE("GPL");
static char buf[100];
static ssize_t flag_read(struct file *file, char __user *ubuf, size_t count, loff_t *ppos)
{
struct file *fp;
loff_t pos = 0;
if(*ppos > 0) return 0;
fp = filp_open("/flag", O_RDWR ,0);
int len = kernel_read(fp, buf, sizeof(buf), &pos);
printk("read: %s\n", buf);
filp_close(fp, NULL);
copy_to_user(ubuf,buf,len);
*ppos = len;
return len;
}
const struct proc_ops myops = {
.proc_read = flag_read
};
static int readfile_init(void)
{
printk("readfile enter\n");
proc_create("flag",0666,NULL,&myops);
return 0;
}
static void readfile_exit(void)
{
remove_proc_entry("flag", NULL);
printk(KERN_INFO "readfile, exit!\n");
}
module_init(readfile_init);
module_exit(readfile_exit);
编译,安装,普通用户无法成功读取到flag:
$ ls -al /flag
---------- 1 root root 23 Aug 5 09:20 /flag
$ cat /flag
cat: /flag: Permission denied
$ sudo cat /flag
flag{this_is_the_flag}
$ make
$ sudo insmod ./readfile.ko
$ cat /proc/flag
killed
$ sudo cat /proc/flag
flag{this_is_the_flag}
所以如果是内核Pwn仍然需要 commit_creds(prepare_kernel_cred(0)) 来提权:
不过既然能读文件,在CTF中直接printk应该也可以,未必非要一个root的用户态shell。
内存调试
CPU在光速的运行,如果没有调试,可能除了上帝,这个世界上没有任何人知道你的代码是怎么运行的
我们自然会对一个不曾见过的东西感到陌生,困惑,甚至恐惧。在平时调试用户态程序时,使用gdb并无法看到内核的内存地址空间,这也使得内核显得有些神秘。每当我们想对内存一探究竟时,必然绕不过调试二字。用户态的调试看起来是理所应当,但其实背后是操作系统内核的支持,所以如果想调试内核本身,则需要内核再往下的部分支持:linux 内核调试方法,这也就是双机调试或者使用qemu调试的道理。如果软件层次没有任何调试方案,还有硬件层次的JTAG以调试你的代码,但我们真的不能简单轻松的看见内核的内存么?这个问题也可以换一种问法:在没有调试器之前,人们都是怎样写代码的呢?当然是log大法:FC/NES 游戏是怎么制作的?。
kmem
在linux一切皆文件的哲学下,其实是有接口可以直接读写内核内存的,但因为安全风险一般不开启这个功能:
- How to use /dev/kmem?
- devmem读写物理内存和devkmem读取内核虚拟内存
- https://wiki.ubuntu.com/Security/Features#dev-kmem
自己构建
因为仅仅只是简单的读写内存,而不是复杂的单步调试,所以就是通过一个proc的接口文件,打印目标内存即可:
https://github.com/xuanxuanblingbling/linux_kernel_module_exercise/blob/master/04.kmem/kmem.c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
MODULE_LICENSE("GPL");
char * addr;
int length;
static ssize_t kmem_write(struct file *file, const char __user *ubuf, size_t count, loff_t *ppos)
{
char buf[0x1000];
copy_from_user(buf, ubuf, count);
sscanf(buf,"%llx %x",&addr,&length);
printk("addr: %llx, length: %x\n",addr,length);
return count;
}
static ssize_t kmem_read(struct file *file, char __user *ubuf, size_t count, loff_t *ppos)
{
printk(KERN_INFO "kmem, read!\n");
if(*ppos > 0) return 0;
char buf[0x1000];
int len = sprintf(buf,"addr: 0x%llx length: 0x%x\n",addr,length);
int i=0;
for(i;i<length;i++){
if((i%8==0) && (i!=0)) len += sprintf(buf+len," ");
if((i%16==0) && (i!=0)) len += sprintf(buf+len,"\n");
len += sprintf(buf+len,"%02X ",addr[i] & 0xff);
}
len += sprintf(buf+len,"\n");
copy_to_user(ubuf,buf,len);
*ppos = len;
return len;
}
const struct proc_ops myops = {
.proc_write = kmem_write,
.proc_read = kmem_read
};
static int kmem_init(void)
{
printk(KERN_INFO "kmem, init!\n");
addr = (char *)printk;
length = 0x20;
proc_create("kmem",0666,NULL,&myops);
return 0;
}
static void kmem_exit(void)
{
remove_proc_entry("kmem", NULL);
printk(KERN_INFO "kmem, exit!\n");
}
module_init(kmem_init);
module_exit(kmem_exit);
这里只实现了读内存,写内存的功能可以自行实现,代码中相关API以及需要注意的问题:
用法:向/proc/kmem写入目标地址和长度,然后在cat这个文件即可,默认会打印printk的内存:
$ make
$ sudo insmod ./kmem.ko
$ cat /proc/kmem
addr: 0xffffffffad396663 length: 0x20
0F 1F 44 00 00 55 48 89 E5 48 83 EC 50 48 89 74
24 28 48 89 E6 48 89 54 24 30 48 89 4C 24 38 4C
$ echo "0xffffffffad396663 0x100" > /proc/kmem
$ cat /proc/kmem
addr: 0xffffffffad396663 length: 0x100
0F 1F 44 00 00 55 48 89 E5 48 83 EC 50 48 89 74
24 28 48 89 E6 48 89 54 24 30 48 89 4C 24 38 4C
89 44 24 40 4C 89 4C 24 48 65 48 8B 04 25 28 00
00 00 48 89 44 24 18 31 C0 48 8D 45 10 C7 04 24
08 00 00 00 48 89 44 24 08 48 8D 44 24 20 48 89
44 24 10 E8 B5 2C 58 FF 48 8B 54 24 18 65 48 33
14 25 28 00 00 00 74 05 E8 50 42 05 00 C9 C3 65
48 8B 04 25 C0 7B 01 00 8B 90 18 09 00 00 48 8D
B0 E8 0A 00 00 48 C7 C7 E0 1F BB AD C6 05 3F A6
D7 00 01 E8 68 FF FF FF E9 48 F3 57 FF 48 C7 C7
A8 20 BB AD 65 48 8B 34 25 C0 7B 01 00 48 81 C6
E8 0A 00 00 E8 47 FF FF FF 41 C7 44 24 18 00 00
00 00 E9 E2 F5 57 FF 55 8B 35 03 32 DC 00 48 C7
C7 20 93 15 AE 48 89 E5 E8 E0 DA 9E FF 5D C3 0F
1F 44 00 00 55 48 C7 C0 EA 91 BF AD 48 C7 C6 01
7E BE AD 48 89 FA 48 89 E5 41 54 F6 47 48 08 49
我们通过startup_64符号,打印一下内核起始地址的内存:
$ sudo cat /proc/kallsyms | grep startup_64
ffffffffac800000 T startup_64
$ echo "0xffffffffac800000 0x100" > /proc/kmem
$ cat /proc/kmem
addr: 0xffffffffac800000 length: 0x100
48 8D 25 51 3F 60 01 48 8D 3D F2 FF FF FF 56 E8
BC 06 00 00 5E 6A 10 48 8D 05 03 00 00 00 50 48
CB E8 EA 00 00 00 48 8D 3D D3 FF FF FF 56 E8 BD
02 00 00 5E 48 05 00 A0 22 2E EB 16 0F 1F 40 00
E8 CB 00 00 00 56 E8 15 30 00 00 5E 48 05 00 00
E1 2D B9 A0 00 00 00 F7 05 CF EF 49 01 01 00 00
00 74 06 81 C9 00 10 00 00 0F 22 E1 48 03 05 9D
9F 61 01 56 48 89 C7 E8 94 01 00 00 5E 0F 22 D8
48 C7 C0 89 00 80 AC FF E0 0F 01 15 70 9F 61 01
31 C0 8E D8 8E D0 8E C0 8E E0 8E E8 B9 01 01 00
C0 8B 05 99 27 90 01 8B 15 97 27 90 01 0F 30 48
8B 25 9A 27 90 01 56 E8 B4 2F 00 00 5E B8 01 00
00 80 0F A2 89 D7 B9 80 00 00 C0 0F 32 0F BA E8
00 0F BA E7 14 73 0D 0F BA E8 0B 48 0F BA 2D DC
9F 61 01 3F 0F 30 B8 33 00 05 80 0F 22 C0 6A 00
9D 48 89 F7 68 07 01 80 AC 31 ED 48 8B 05 36 27
到此,我们不需要什么qemu,kdb,kgdb,也可以直接看到我们本机内核的内存。
内核本体
现在让我们从正向开发的视角转到逆向视角:认识编译好的内核二进制
有了读取内核内存的能力后,是不是迫不及待想看看本机内核二进制的真面目了呢?其实不必dump内存,内核二进制本身就可以通过文件系统访问到,它就在/boot目标下:
$ uname -r
$ sudo file /boot/vmlinuz-5.11.0-25-generic
/boot/vmlinuz-5.11.0-25-generic: Linux kernel x86 boot executable bzImage
我们可以按照如下方法分析它:
使用的两个工具:
内核符号表的原理:内核符号表的生成和查找过程
- extract-vmlinux: 将vmlinuz解压成vmlinux
- vmlinux-to-elf: 恢复vmlinux为IDA可以解析其符号表的ELF,运行时间较长
$ ./extract-vmlinux.sh ./vmlinuz-5.11.0-25-generic > vmlinux
$ vmlinux-to-elf ./vmlinux ./vmlinux.elf
三个文件的file结果:
$ file vmlinuz-5.11.0-25-generic
vmlinuz-5.11.0-25-generic: Linux kernel x86 boot executable bzImage, version 5.11.0-25-generic (buildd@lgw01-amd64-038) #27~20.04.1-Ubuntu SMP Tue Jul 13 17:41:23 UTC 2021, RO-rootFS, swap_dev 0x9, Normal VGA
$ file ./vmlinux
./vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, BuildID[sha1]=c0263a3075bc0a9388365ddf35ab5422da3356a9, stripped
$ file ./vmlinux.elf
./vmlinux.elf: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, BuildID[sha1]=c0263a3075bc0a9388365ddf35ab5422da3356a9, not stripped
然后使用IDA分析最后的生成的vmlinux.elf:
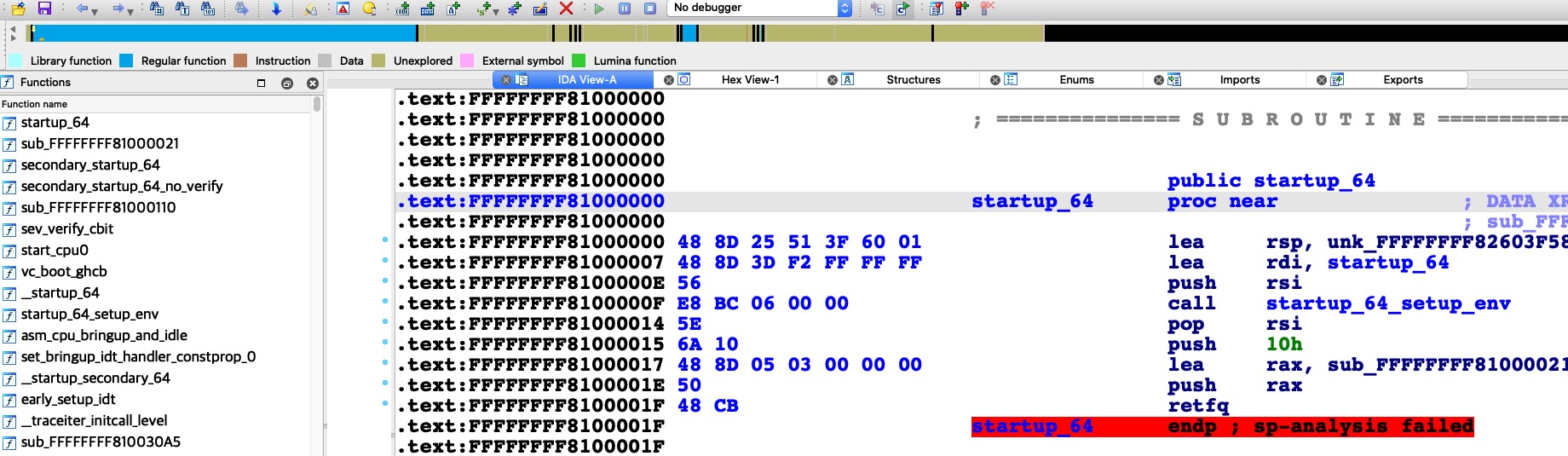
可以看到入口是startup_64,对比之前打印的内存结果,豁然开朗:
$ sudo cat /proc/kallsyms | grep startup_64
ffffffffac800000 T startup_64
$ echo "0xffffffffac800000 0x100" > /proc/kmem
$ cat /proc/kmem
addr: 0xffffffffac800000 length: 0x100
48 8D 25 51 3F 60 01 48 8D 3D F2 FF FF FF 56 E8
BC 06 00 00 5E 6A 10 48 8D 05 03 00 00 00 50 48
CB E8 EA 00 00 00 48 8D 3D D3 FF FF FF 56 E8 BD
因为存在内核基址的随机化,所以IDA结果和实际不同,至此我们可以放心的看IDA中的逆向结果来认识内核二进制了。